
El formato de datos bfloat16
Revisando cómo representamos los números en una máquina, y cómo funciona el formato de datos bfloat16 para redes neuronales.


A los grandes modelos de lenguaje (LLMs) no se les llama grandes por nada: estas redes neuronales artificiales contienen desde miles de millones hasta cientos de miles de millones de parámetros, que son los que gobiernan el funcionamiento de la red. Un LLM que hoy día se puede considerar “pequeño” como Llama-3.1-8B contiene aproximadamente 8 mil millones de parámetros, mientras que si nos vamos a modelos realmente grandes como Llama-3.1-405B ya llegamos a los 405 mil millones. Estos tamaños tan descomunales de modelos dificultan su transferencia y almacenamiento, pero también sus procesos de entrenamiento e inferencia debido a la gran cantidad de cálculos que implican.
Es por ello que en los últimos años se han desarrollado una serie de tipos de datos especializados para deep learning, siendo el más popular bfloat16. Estos formatos no son sino maneras particulares de representar los valores de los parámetros de la red, de manera que ocupen lo menos posible sin perjudicar los procesos de aprendizaje e inferencia. En este post vamos a explicar en qué consiste el formato bfloat16, haciendo antes un repaso a cómo se representan los diferentes tipos de números en un computador.
Números enteros

Un número entero, habitualmente representado por la abreviatura int, representa un número que no tiene decimales. Dicho de otra manera, un número entero puede ser cualquier número natural (0, 1, 2, …), pero también sus negativos (-1, -2, -3, …). Aunque esto no parece encerrar gran misterio, la dificultad que entraña representar un número entero es que la cantidad de números enteros es infinita1. Esto significa que alguien podría demandarnos almacenar en un ordenador un número entero con una cantidad larguísima de cifras, y tendríamos que ver cómo apañárnoslas para ello. Pero es que después podría aparecer otro fulano exigiendo que almacenemos un número el doble de grande, y tendríamos un problema el doble de grande. No importa por tanto cuánta memoria tenga un ordenador, siempre habrá un número tan grande que no tendremos forma de almacenar.
Por tanto no nos queda otra que capitular, y asumir que va a haber números tan enormes que no vamos a poder guardar. Lo que haremos por tanto será decidir de antemano cuánta memoria vamos a querer dedicar a almacenar un número entero, y tratar de aprovecharla de la mejor manera posible. Esta cantidad de memoria depende del lenguaje de programación empleado, pero una elección bastante habitual es emplear 32 bits, como en el siguiente ejemplo:

Cuando trabajamos con números enteros no negativos (a veces llamados unsigned) la representación en bits es sencilla, correspondiendo a la siguiente ecuación en el caso de usar n bits:
O dicho de otra manera, el número decimal que representa un entero en bits se construye como una suma del valor que representa cada bit, los cuales siguen las sucesivas potencias de 2:
El bit en la posición 0 vale 1 (20) si está activado, 0 si no lo está.
El bit en la posición 1 vale 2 (21) si está activado, 0 si no lo está.
El bit en la posición 2 vale 4 (24) si está activado, 0 si no lo está.
…
El bit en la posición n-1 vale 2n-1 si está activado, 0 si no lo está.
Siguiendo este esquema, el número binario de la imagen anterior tomaría el valor 230 + 213 + 211 + 25 = 1073741824 + 8192 + 2048 + 32 = 1073752096.
Echando cuentas se puede ver que el emplear 32 bits en este formato de datos admite representar números enteros desde el 0 (todos los bits a 0) hasta el 4294967295 (todos los bits a 1). Que este último número sea exactamente 232 - 1 no es casualidad: dado que contamos con 32 bits y cada bit puede tomar dos valores, la combinatoria nos dice que podemos configurar esta cadena de bits de 2·2·2·…·2 = 232 maneras. Puesto que utilizamos la cadena de todos 0 para representar el número entero 0, nos quedan 232 - 1 posibles combinaciones de bits para representar números positivos, y de ahí el tope del máximo representable. En términos generales, si usáramos n bits para almacenar un número entero podríamos representar cualquier número entre el 0 y el 2n - 1.
Poniéndonos negativos

Cuando necesitamos representar números tanto positivos como negativos el formato de datos anterior requiere de algunos cambios. Hay varios paradigmas para codificar el signo, pero el más fácil de entender es la representación de signo y magnitud:
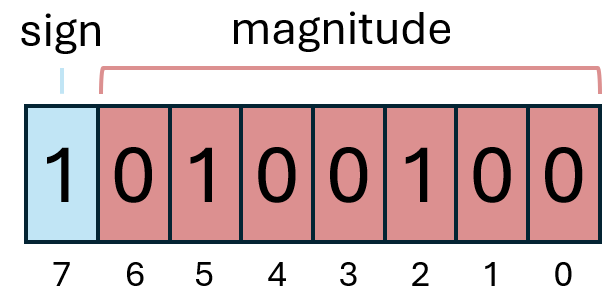
En el ejemplo usamos solo 8 bits para facilitar los cálculos que haremos, pero en general suelen usarse 32 bits para codificar enteros con signo.
En esta representación se reserva un bit para indicar cuál es el signo del número. En la imagen de ejemplo, el bit de signo es el 7. Este bit tomará el valor 0 para números positivos, y el valor 1 para números negativos. El resto de bits se utilizan para la magnitud del número, de la misma forma que hemos visto en el caso de los números enteros sin signo. De esta manera, la cadena de bits de la imagen se interpretaría así:
Los bits de magnitud forman el valor 25 + 22 = 32 + 4 = 36.
Dado que el bit de signo es un 1, el número debe interpretarse como negativo. Así que el resultado es -36.
Puesto que hemos tenido que invertir un bit para el signo, el número de bits empleados para representar la magnitud se ha visto reducido a 7, y por tanto este tipo de datos solo permite representar números entre el 2-7+1 y el 27-1.
Algo peculiar de esta representación es que existen dos formas de codificar el número 0: como un bit 0 en el signo y todo bits 0 en la magnitud (+0), o como un bit 1 en el signo y todo bits 0 en la magnitud (-0). Esta observación puede parecer pijotera, pero es un hecho relevante cuando trabajamos con tipos de datos pequeños. Por ejemplo, si solo pudiéramos usar 4 bits para representar un número, estaríamos malgastando una de las 24 = 16 combinaciones posibles de bits, lo que equivale al 6.25% de la memoria.
Una alternativa que aprovecha al máximo el uso de la memoria es la representación binaria sesgada (offset binary). En ella todos los bits se emplean para representar la magnitud, pero se trata de una magnitud sesgada.
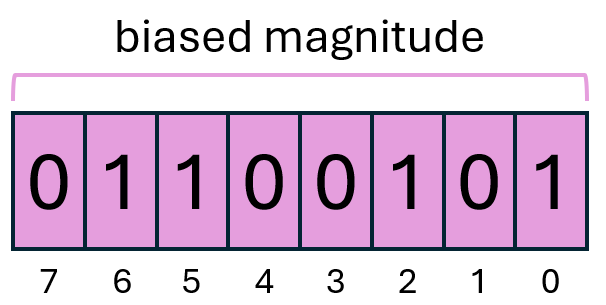
En esta representación el número se comienza interpretando de la misma manera que si fuera un entero sin signo, pero al resultado se le resta un valor fijo, que suele ser el valor medio del rango representado: si contamos con 2n bits se suele restar 2n-1:
En el ejemplo de la imagen tendríamos 26 + 25 + 22 + 20 - 27 = 64 + 32 + 4 + 1 - 128 = -27. Usando este formato podemos representar números entre -2n-1 (todo bits a 0) y 2n - 1 - 2n-1 (todo bits 1). No se pierde ningún valor por representar el 0 dos veces.
Ya como colofón de los números enteros, conviene mencionar que aunque la representación binaria sesgada es útil, requiere realizar una resta cada vez que se va a utilizar el número representado, lo cual añade coste computacional: pagamos en ciclos de reloj la ganancia en memoria. Es por ello que existe la representación en complemento a dos, que de forma muy inteligencia permite aprovechar al máximo la memoria sin requerir de cálculos extra:
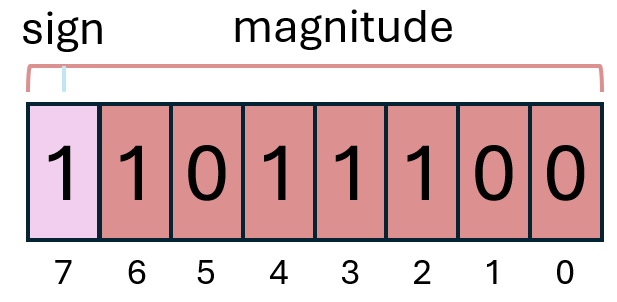
El reparto de bit para signo y bits para magnitud es similar al empleado en el formato de signo y magnitud, pero en esta ocasión el bit de signo también contribuye a la magnitud, aunque de forma negada. Esto significa que la ecuación para obtener el valor del número es ligeramente diferente a la de los enteros sin signo:
En el ejemplo de la imagen tendríamos por tanto que el valor representado es -27 + 26 + 24 + 23 + 22 = -128 + 64 + 16 + 8 + 4 = -36. Es el mismo valor que en el ejemplo de la representación de signo y magnitud, solo que en complemento a dos toma un aspecto muy diferente.
Aunque descodificar el formato de complemento a dos es poco intuitivo para los humanos, resulta trivial para una máquina. Y nos aporta varias ventajas sobre el formato de signo y magnitud:
No existen dos representaciones para el valor 0. El 0 se representa solo con el bit de signo a 0 y todos los bits de magnitud a 0. Si ponemos el bit de signo a 1 y los de magnitud a 0 obtenemos el número -27 = -128, que es el valor más negativo representable con 8 bits.
Hacer operaciones entre números con esta representación es muy barato computacionalmente. Sumar dos números en este formato no requiere de ninguna operación más allá que hacer una suma binaria estándar, ignorando desbordamientos. También existen algoritmos eficientes para calcular restas y multiplicaciones.
El formato de coma flotante

En machine learning y muchas otras aplicaciones de la computación no es suficiente con los números enteros, y necesitamos también representar números reales, esto es, con decimales. Las redes neuronales son un ejemplo especialmente notorio de esto, ya que requieren calcular derivadas para optimizar sus parámetros, y la derivación se define sobre números reales2. Por tanto vamos a revisar cómo tratar este caso.
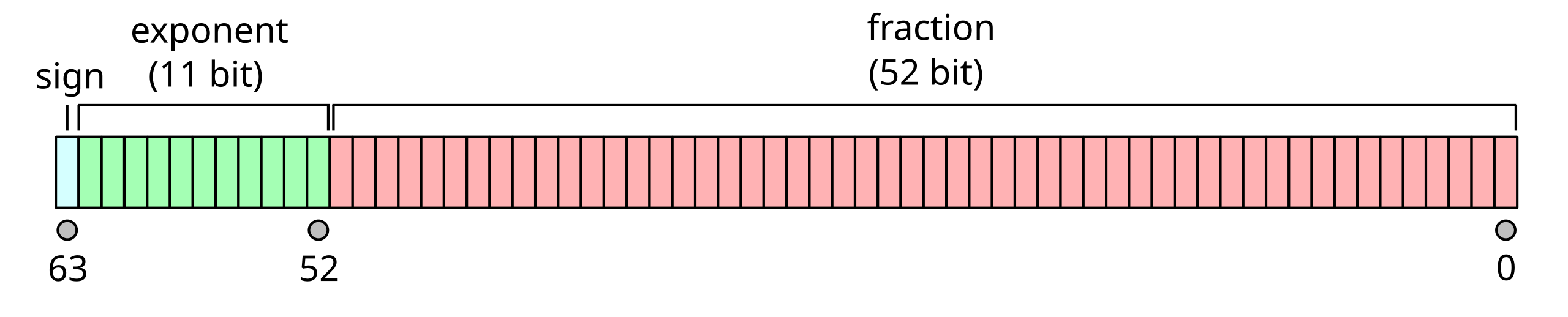
Cuando queremos almacenar en un computador un número real, que pueda tomar un valor con cualquier número de decimales, es habitual utilizar la representación en coma flotante. De nuevo, el caso más habitual es utilizar 32 bits para representar esta clase de número, comúnmente conocido como float32 o fp32, y que toma la siguiente forma:

{kind=link}
El bit de mayor valor (31) se utiliza para representar el signo del número, de forma similar a la representación de signo y magnitud vista arriba: 0 se interpreta como un número positivo, y 1 como un número negativo.
Los siguientes 8 bits (30 al 23) codifican el exponente del número.
Los 23 bits restantes (22 a 0) codifican la fracción del número.
Para explicar el efecto de estos tres componentes, lo mejor es ir paso a paso. Inicialmente, el número representado se toma como un 1 (en binario). Sobre este valor se aplican las siguientes transformaciones:
Inicialización: empezamos el algoritmo partiendo del número 1₂. El subíndice ₂ denota aquí que se trata de un número binario.
Procesar la fracción: los bits de la fracción se añaden como decimales al número. En el ejemplo de la imagen, el número pasaría a ser 1.01000000000000000000000₂ = 1.01₂.
Desplazar la coma: el exponente nos marca cuántas posiciones debemos desplazar ahora la coma, haciendo así honor al nombre de “coma flotante”. Esto se hace interpretando estos bits como un entero con signo en formato en representación binaria sesgada. En el ejemplo de la imagen tenemos los bits 01111100₂ en el exponente, que dan el valor 124 - 27 = 124 - 127 = -3. Esto nos lleva a desplazar la coma 3 posiciones a la izquierda. Dado que en el paso anterior obtuvimos el valor 1.01₂, ahora tendremos 0.00101₂.
Aplicar el signo: en el ejemplo de la imagen el bit de signo es 0, lo que implica un número positivo, así que seguimos con 0.00101₂.
Pasar a base 10: como paso final transformamos el número binario obtenido a decimal, de forma similar a una representación de un entero sin signo, solo que ahora los bits después de la coma utilizan potencias negativas de dos. En el ejemplo tendríamos 0.00101₂ = 20 0 + 2-1 0 + 2-2 0 + 2-3 1 + 2-4 0 + 2-5 1 = 0.15625.
Y de esta forma es posible guardar un número real en un computador... ¡aunque no cualquier número! La cantidad de bits que dedicamos al exponente limita el rango del número: cómo de grande o pequeño (cercano a 0) puede llegar a ser. Por su parte, los bits usados para la fracción limitan la resolución del número, esto es, con cuántas cifras de precisión podemos expresarlo. En el caso de usar el esquema de 32 bits mostrado arriba, el rango oscila entre 2-126 y 2127. En cambio el número de cifras (binarias) es de 24, debido a que se tienen 23 bits para estas cifras más el 1 que se coloca siempre. Al convertir este número a decimal en el último paso estas cifras binarias se convierten en log10 (223) ≃7.225 cifras decimales.
En algunas aplicaciones científicas este nivel de rango no es lo bastante grande, o la resolución no es lo suficientemente precisa, por lo que existen otras representaciones en coma flotante que hacen uso de 64-bits, popularmente conocidas como el tipo de datos double. En casos donde se requiera un rango o precisión extraordinarios existen también representaciones de 128-bits, aunque estas no suelen estar soportadas a nivel de hardware y deben simularse por software.
{kind=link}
También es destacable que el formato en coma flotante se reserva algunas configuraciones de bits para representar números especiales:
El número 0 se representa poniendo bits a 0 en todo el exponente y la fracción. El valor del signo diferencia entre +0 y -0, algo que no tenía sentido para números enteros, pero que sí puede ser útil en números reales para representar un límite a 0 por la izquierda o por la derecha. No obstante, la mayoría de implementaciones de este formato suelen devolver True al preguntar si +0 es igual a -0.
El valor ∞ (infinito) puede representarse marcando a 1 todos los bits del exponente y a 0 los de la fracción. El bit de signo se usa para diferenciar si estamos hablando de +∞ o -∞.
El valor NaN (Not a Number) se denota poniendo bits a 1 en todo el exponente, y cualquier cosa que no sean todo bits 0 en la fracción. Este valor se utiliza para representar el resultado de operaciones matemáticas que no están definidas para los números reales, como 0/0 o √(-1). En el mundo de la ciencia de datos también es frecuente usarlo para denotar valores faltantes.
Números en coma flotante para machine learning: bfloat16

Un descubrimiento relevante en la comunidad de los gráficos por ordenador, pero también del aprendizaje automático, fue que el formato estándar para representar los números en coma flotante está infrautilizado en este tipo de aplicaciones. Desde el punto de vista del machine learning podemos dar dos argumentos que apoyan esta idea:
No nos es útil contar con un gran rango (bits de exponente). En el formato en coma flotante de 32 bits podemos representar números en magnitudes desde el 1e-45 hasta el 3.40e+38. Pero este rango tan amplio significa que en nuestro modelo hay parámetros que podrían llegar a tener una influencia 1083 veces mayor que otros. Esto es un absurdo, porque fácilmente podemos llegar a una situación donde unos pocos parámetros dominan completamente todo el comportamiento del modelo. Y si ese fuera el caso, ¿para qué necesitamos todos los demás parámetros? Podríamos crear un modelo más pequeño, solo con los parámetros dominantes, que funcionaría esencialmente igual.
No es necesario tener una gran resolución (bits de fracción) para representar los parámetros de un modelo. Puesto que un proceso de inferencia en un modelo consiste en aplicar cálculos que combinan desde centenares a cientos de millones de parámetros, y dado que ya hemos concluido que estos parámetros deberían tener un rango similar, los bits menos significativos de un parámetro concreto tienen una influencia prácticamente nula en el resultado final.
Es por ello que en machine learning es posible utilizar tipos en coma flotante con precisión reducida, sin perder por ello rendimiento en el modelo resultante.
Un formato en coma flotante con precisión reducida y de uso general es el formato de 16 bits, también conocido como de precisión half o float16, y que reduce tanto el rango (exponente) como la resolución (fracción):
{kind=link}
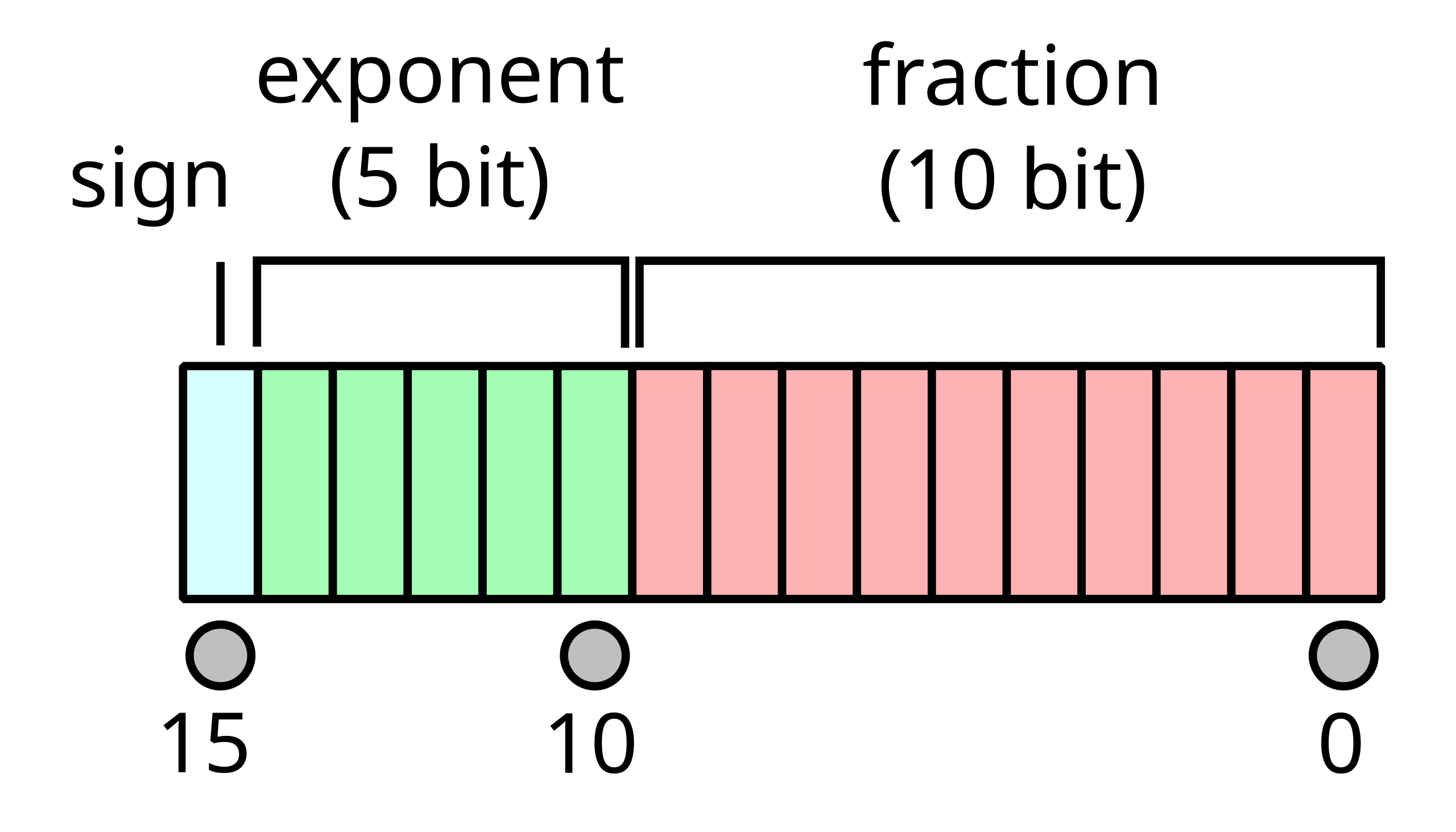
No obstante, en machine learning, y concretamente redes neuronales, es más común emplear una redistribución de bits diferente, en el formato conocido como brain floating point o bfloat16:

En este formato no se reduce el rango (exponente), sino únicamente la resolución (fracción). La ventaja principal sobre el formato anterior es que convertir números desde fp32 a bfloat16 es muy sencillo y barato: basta con descartar los últimos 16 bits de la fracción.
El formato bfloat16 es ampliamente soportado no solo a nivel de librerías software de machine learning como Pytorch, Tensorflow o MKL, sino también a nivel hardware: GPUs de Nvidia, procesadores Intel Xeon, TPUs de Google, chips AWS Inferentia y Trainium, M2 de Apple e incluso FPGAs. Es por ello que bfloat16 se ha convertido en el estándar de facto para el mundo de las redes neuronales artificiales. Y no solo por su ahorro en memoria: el hecho de tener que hacer cálculos con números más cortos hace que el entrenamiento y la inferencia sean también más rápidos.
Más allá de bfloat16

¿Con bfloat16 se acaba la película? Lo cierto es que no, pues en los últimos años han aparecido una gran cantidad de técnicas de cuantización, que permiten comprimir aún más los formatos de datos. Estas técnicas son cruciales a día de hoy para poder ejecutar LLMs de gran tamaño a un precio abordable, o poder desplegar LLMs de tamaño medio en hardware de consumo. Puedes leer más sobre ellas en el siguiente artículo:
Poniéndonos más precisos, la cantidad de números enteros es ℵ0 (aleph cero), la clase de infinito más “básica”. Pero los detalles de esto los dejo (tal vez) para otro post.
Existen extensiones del concepto de derivadas para los números enteros, pero estas no se utilizan en el mundo del machine learning, por lo que no vamos a entrar en ellas.
Imágenes de acompañamiento creadas con el modelo FLUX.1 Schnell.
Vaya bien que explicas las cosas Álvaro!