
BaLLMatro
Expectativas infladas y pinchadas, benchmaxxing, y una nueva forma de poner a prueba a los LLM del estado del arte


Nos dijeron que GPT-5 cambiaría el mundo. Que tendría la inteligencia de un doctor (PhD) para tareas específicas. Que tenía nivel de medalla de oro en competiciones de matemáticas. Y en general, escuchamos voces por toda la red contándonos que automatizaría gran parte de los trabajos, entre ellos el del desarrollo de software. A día de hoy, varios meses tras la inauguración de este sistema de IA, nada de eso ha ocurrido.
Pueden ustedes cambiar GPT-5 por las últimas versiones de Gemini, Claude, Grok o cualquier otro LLM: el argumento será el mismo. En los últimos años nos hemos acostumbrado a este ciclo continuo en el que el siguiente gran LLM será el que producirá el cambio de paradigma, solo para que luego esas expectativas no se cumplan. Pero estén tranquilos porque seguro que el LLM después de este de verdad será el bueno.
Lo cierto es que en el fondo ni siquiera es un problema de capacidades. Cada nueva generación de LLM es mejor que la anterior, esto puede comprobarse tanto en el uso cotidiano como en el profesional. El problema es el nivel al que se inflan una y otra vez las expectativas, y la consecuente decepción cuando estas no se cumplen. Son muchos los actores que contribuyen a este ciclo: las propias empresas que crean los LLM, sus inversores, la prensa… mención especial a los “AI bros” que viven de vender charlas y cursos sobre cómo hacer IA, pero no de hacerla en producción real.
Y los benchmarks. Porque la disciplina del aprendizaje automático ha avanzado en gran parte gracias a los benchmarks, así que, ¿quién no va sentirse confiado cuando le enseñan que el nuevo LLM es imbatible en matemáticas, comprensión del lenguaje, conocimiento general y desarrollo de software?
Del benchmarking al benchmaxxing
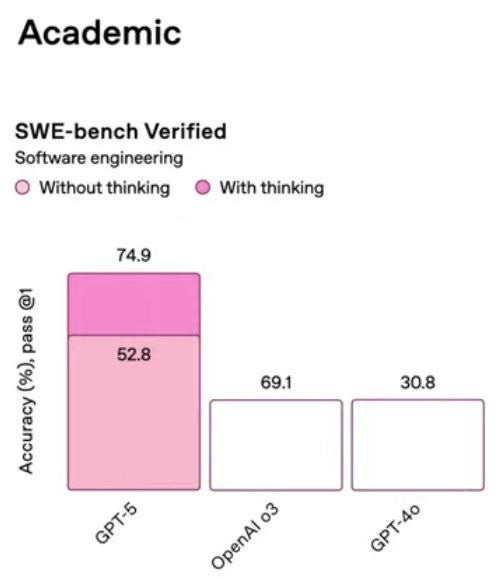
Si repasamos los resultados de GPT-5 publicados por la propia OpenAI nos encontramos con cifras impresionantes:
100% de acierto en la competición de matemáticas AIME 2025.
89.4% de acierto en un test con preguntas de nivel de doctorado, creado por especialistas: GPQA Diamond.
74.9% de resolución en las issues del benchmark de desarrollo de software SWE-bench Verified.
42% de acierto en el Humanity’s Last Exam, otro benchmark de preguntas de nivel experto, de todo tipo de temática.
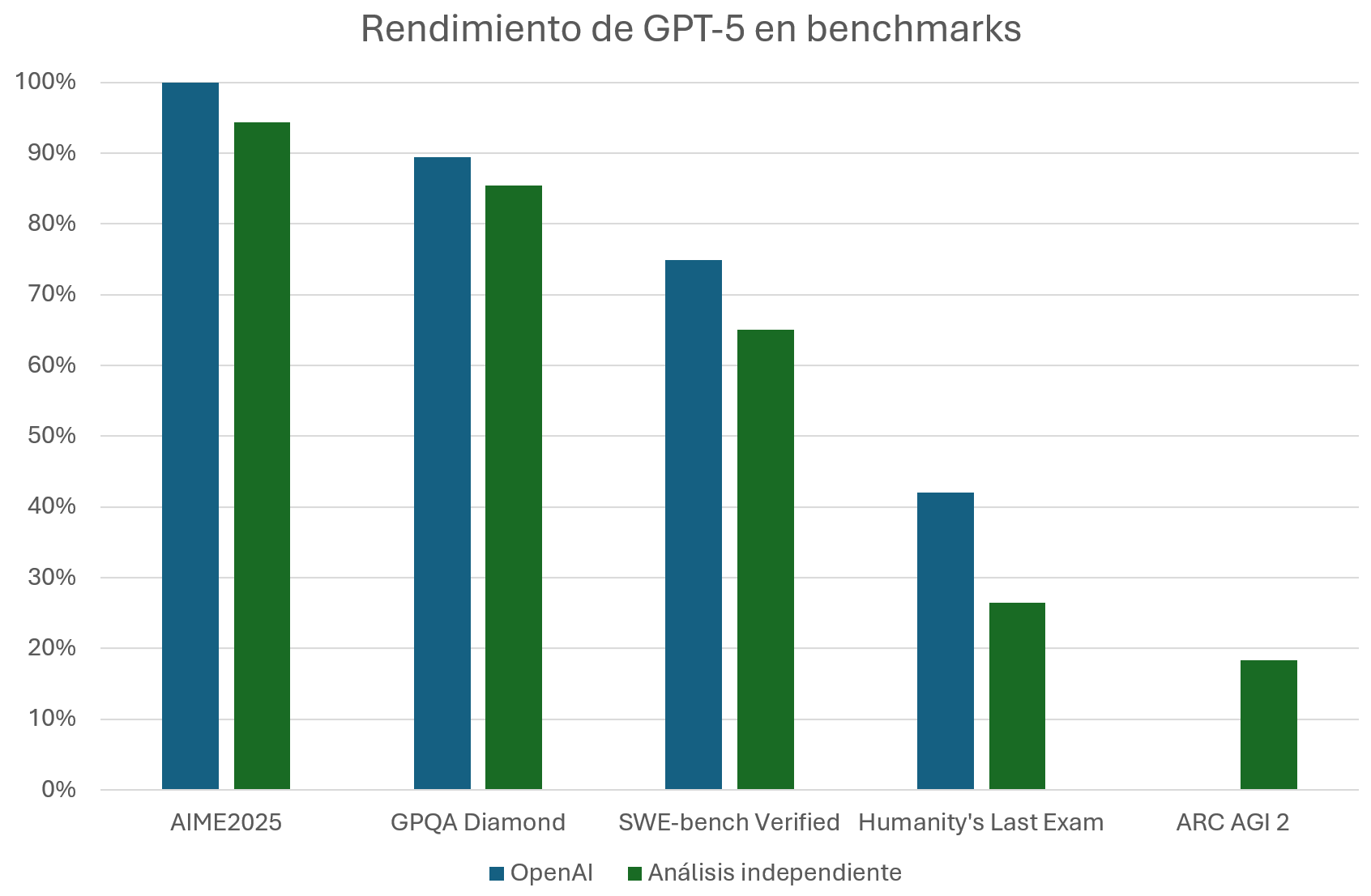
Lo peculiar del asunto es que si consultamos el rendimiento sobre estos benchmarks evaluados de manera independiente nos encontramos conclusiones algo diferentes:
AIME 2025: GPT-5 se queda en una puntuación de 94.3%.
GPQA Diamond: a fecha de publicación de GPT-3, Grok 4 era el modelo con mejor rendimiento, con un 87.7%, quedando GPT-5 ligeramente por detrás con un 85.4%.
SWE-bench Verified: a fecha de publicación de GPT-3, Claude 4.5 Sonnet era el mejor modelo, resolviendo un 70.6% de la issues mediante una integración con un agente mínimo. GPT-5 obtiene un 65%.
Humanity’s Last Exam: GPT-5 solo alcanza una puntuación del 26.5%.
ARC-AGI 2, un benchmark especialmente complejo para medir inteligencia, no ha sido mencionado por OpenAI en la publicación de GPT-5. Pero podemos comprobar que en su versión “Pro” solo obtiene un 18.3% de éxito en la resolución de las tareas.
Gráficamente tendríamos esta diferencia entre rendimientos declarados por los desarrolladores y medidos de manera independiente.
Pero incluso teniendo en cuenta esta caída de rendimiento, los resultados siguen siendo impresionantes. ¿Cómo no va a ser inteligente un sistema que resuelve 19 de cada 20 problemas de matemáticas, acierta 8 de cada 10 cuestiones extremadamente complejas, y soluciona de forma autónoma el 65% de las issues de software? Y a pesar de estos resultados, todos somos conscientes de las sandeces supinas que pueden soltar los LLM en el momento más inesperado.
Hay varios motivos que pueden explicar este comportamiento. El primero es que, no lo olvidemos, los LLM no tienen una inteligencia comparable a la nuestra: solo han aprendido a imitar e interpolar lo que han visto durante su entrenamiento. Así pues, nos encontraremos con auténticos descalabros cuando les consultemos por asuntos fuera de lo que está recogido en internet o sus fuentes de entrenamiento. Es a lo que Andrej Karpathy se refería cuando en su resumen de 2025 hablaba de “inteligencia dentada” (jagged intelligente), y que anteriormente Ethan Mollick ya había introducido como “frontera dentada” (jagged frontier).
El otro motivo es el que ha venido a acuñarse con el término de benchmaxxing. Y es que los creadores de los LLM tienen un evidente interés por salir bien posicionados en los benchmarks de moda del momento, por lo que pondrán su empeño en maximizar los resultados conseguidos en los mismos. Esto puede ocurrir de varias formas:
De manera deshonesta, incluyendo el dataset del benchmark dentro de los datos de entrenamiento. Pero vamos a suponer que este no es el caso.
Mediante la inclusión en los datos de entrenamiento de datasets similares. Por ejemplo, si queremos obtener un buen resultado en AIME, podemos perfectamente recopilar libros de texto de matemáticas y una gran cantidad de ejercicios con los que entrar al LLM.
Por filtrado a internet. Una vez que un dataset se publica de forma abierta en internet, eventualmente pasará a formar parte de los datos que los crawlers recogen, y a su vez de los volcados masivos de internet que se emplean para entrenar los LLM. Este tipo de filtrado del target es difícil de prevenir, ya que puede ocurrir incluso si los creadores del LLM no son conscientes de él.
Siendo el segundo motivo el que probablemente explica el rendimiento tan optimista de los LLM en benchmarks públicos, el tercer motivo también tiene su impacto, y es seguramente una de las razones por las que los benchmarks que ya tienen cierta antigüedad están totalmente saturados, además de las mejoras que incorporen los propios LLM.
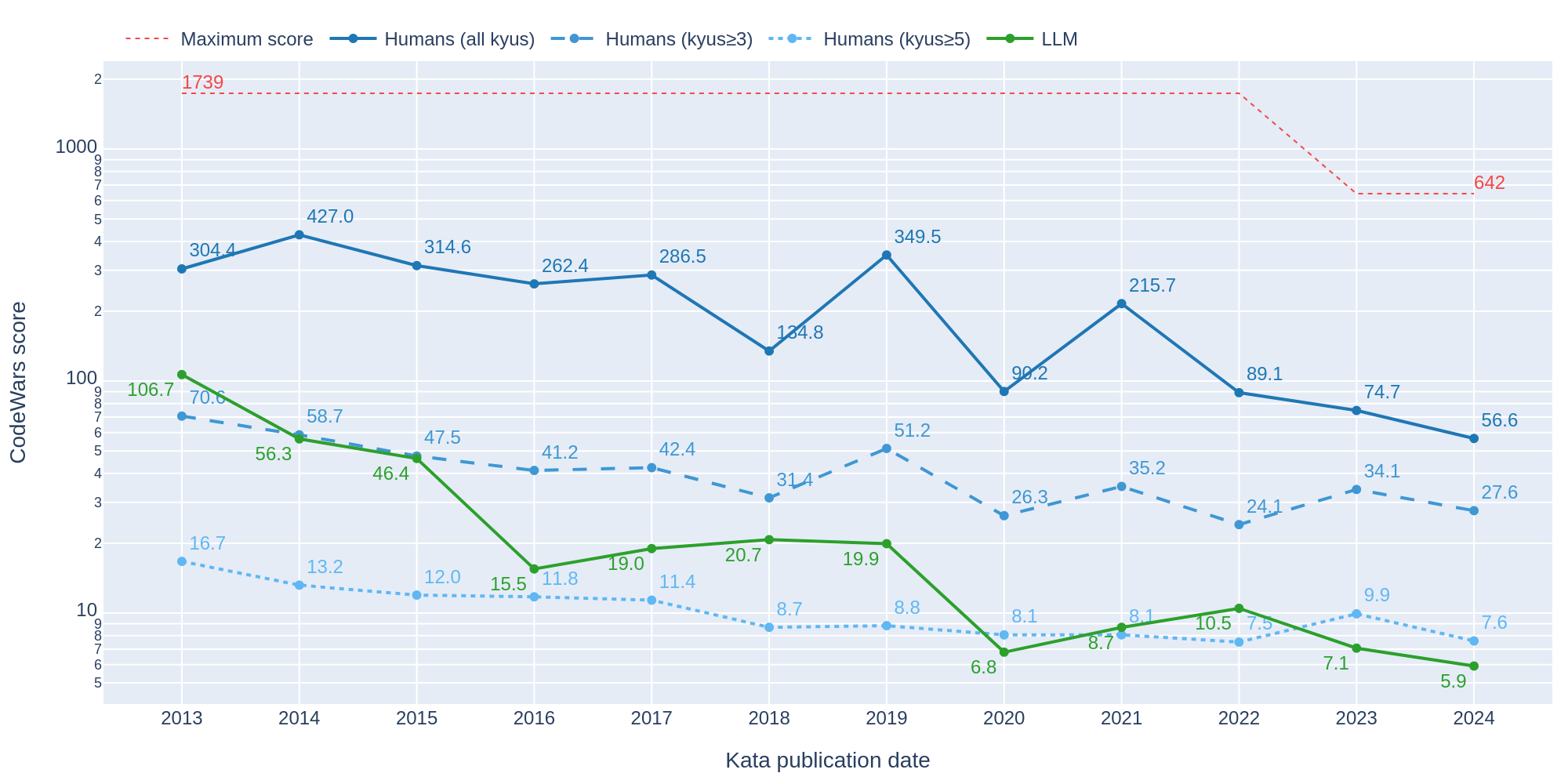
En el artículo con el que inauguré este blog, hace ya algo más de un año, analicé este problema del filtrado de benchmarks para el caso de los desafíos de programación, observando una tendencia muy clara a que el LLM fuera más capaz de resolver desafíos de mayor antigüedad, así como una clara incapacidad de resolver problemas muy complejos o en lenguajes de programación con poco código open-source disponible. Una de las críticas que recibí a esta investigación fue que los resultados eran así de pobres porque no estaba usando el modelo más grande/reciente disponible. Y volvemos así al punto de inicio del artículo: “este modelo no es el bueno, pero el siguiente sí, ese ya sí que funciona. De verdad de la buena.”
¿Cómo resolver el benchmaxxing?

Este es un desafío muy complejo, y sin solución clara a día de hoy. Podríamos decir que hay 3 grandes estrategias a la hora de evaluar las capacidades de un LLM.
La primera serían las pruebas verificables, como GPQA Diamond, Humanity’s Last Exam o ARC AGI, para las cuales puede comprobarse mediante un proceso determinista y barato si la respuesta del LLM es correcta. Los dos primeros de estos datasets intentan plantear preguntas “a prueba de Google”, ya que estas se escogen de forma que un no experto en el tema no logre resolverlas, incluso con la ayuda de un buscador web. En cierto modo, lo que se está midiendo aquí es si el LLM es un “mejor buscador” o si realmente tiene capacidades de razonamiento para llegar a la conclusión correcta sin haber visto la solución. Por otro lado, en el caso de ARC AGI el enfoque es diferente, y se buscan pruebas que sean resolubles para un humano medio, pero muy difíciles para un LLM. Sin embargo, todas estas evaluaciones no están libres de los problemas de filtrado mencionados antes, y es probable que acaben saturados al igual que otros benchmarks anteriores, como Open LLM Leaderboard.
En segundo lugar tendríamos el método de los LLM como juez, donde el LLM siendo evaluado se pone a prueba en una serie de preguntas de respuesta abierta, y es otro LLM el que puntúa esa respuesta en base a su similaridad con la respuesta esperada, o siguiendo una serie de criterios detallados en un prompt. Esta aproximación es frecuente a la hora de evaluar LLM de pequeño tamaño, usando un LLM mucho más grande como juez, o para aplicar técnicas de aprendizaje por refuerzo (como se hizo en DeepSeek), pero se queda corta si queremos evaluar LLM del estado del arte.
Por último, existe también la evaluación por humanos, similar a la anterior pero con grandes grupos de personas haciendo el papel de jueces, lo que implica un coste grande en horas de trabajo humano. Este es el sistema empleado por LMArena, el cual no ha estado exento de críticas por haber permitido realizar tests privados a algunas grandes organizaciones de manera previa a publicar los resultados de sus últimos LLM.
Como vemos, ninguno de estos sistemas ha demostrado ser la solución, y es por ello que continúan coexistiendo. No obstante, en términos de facilidad de evaluación, las pruebas verificables son especialmente interesantes porque pueden ejecutarse de manera barata y reproducible, al contrario que las evaluaciones por LLM o humanos, y esto a su vez permite usarlas también para mejorar los propios LLM mediante algoritmos de aprendizaje por refuerzo (el llamado Reinforcement Learning from Verifiable Rewards). El problema es que la construcción de estas pruebas para evaluación cada vez es más costosa, al ser requisito imprescindible el evitar crear pruebas que puedan contestarse con información ya existente en internet, y por tanto disponible para los LLM actuales o futuros. A este respecto son especialmente interesantes lo que podríamos llamar pruebas procedurales.
Evaluaciones procedurales

He escogido este nombre a falta de un estándar, basándome en un concepto conocido en el diseño de videojuegos: la generación procedural. La idea fundamental es no crear una serie de preguntas tipo test sobre las que evaluar el LLM, sino desarrollar un algoritmo capaz de generar nuevos tests de forma automatizada, e idealmente ilimitada.
Esto puede parecer algo complejo, pero en realidad existen formas fáciles de crear tests de este tipo. Por ejemplo, podemos generar dos números aleatorios y pedirle a un LLM que calcule el resultado de multiplicarlos. Dado que con programación estándar podemos calcular fácilmente el resultado de esta multiplicación, podemos verificar de manera trivial si el LLM encuentra la solución correcta.
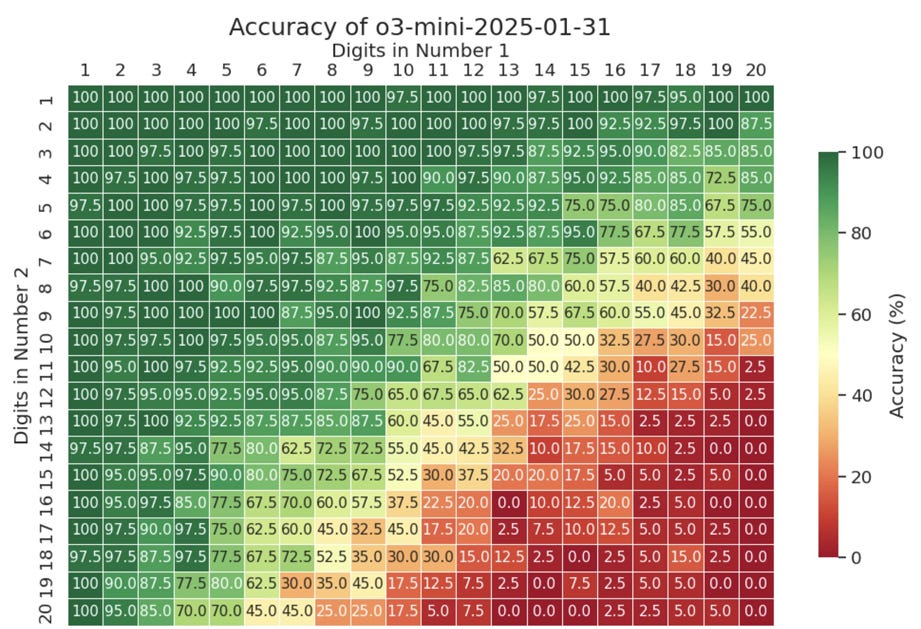
No verán esta gráfica en ningún reporte de resultados de un LLM. Y en cierto modo tiene sentido: pretender usar un LLM como calculadora es matar moscas a cañonazos, gastando para ello una gran cantidad de recursos computacionales y sin garantías de resultados correctos. Pero aunque sea un caso de uso absurdo de esta tecnología, al mismo tiempo es el elefante en la habitación que demuestra que un LLM como tal no puede llegar a ser una Inteligencia Artificial General. Da igual lo potente que sea, podemos seguir añadiendo dígitos hasta volver a encontrar un punto de fallo en el momento en que las cifras involucradas estén muy fuera de los datos de entrenamiento.
Algo más interesantes y ricos en contenidos son las pruebas diseñadas en el paper de Apple titulado The Illusion of Thinking (Shojaee et al). En él se crean 4 tipos de puzle que se presentan al LLM para que trate de resolverlos, incluyendo las míticas torres de Hanoi. Para que el LLM pueda entender y trabajar los puzles, se representan en modo texto, y se indica al LLM mediante prompting cómo debe declarar los pasos a realizar, con el objetivo de resolver el puzle.
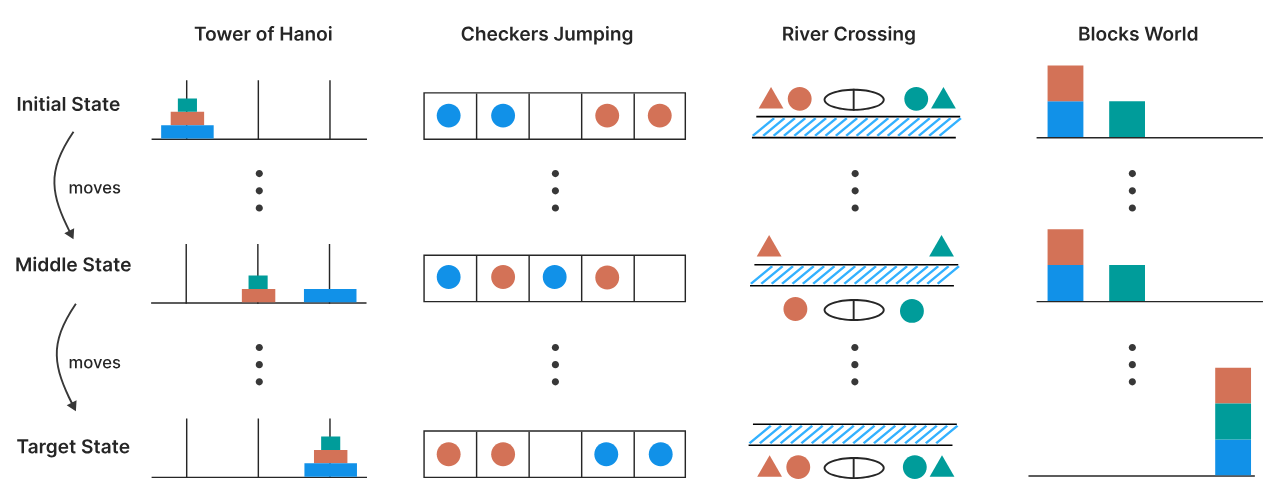
Lo interesante de estos puzles es que su complejidad es configurable mediante un simple cambio de parámetros. Por ejemplo, en las torres de Hanoi puede aumentarse el número de discos que componen la torre, teniendo que para n discos el número mínimo de movimientos para resolver el puzle son 2n - 1 movimientos de disco. De esta forma, añadiendo más discos conseguimos que el problema se vuelva exponencialmente más complejo.
Pues bien, al poner a LLM de tipo “razonador” del estado del arte a resolver estos puzles los resultados son catastróficos:
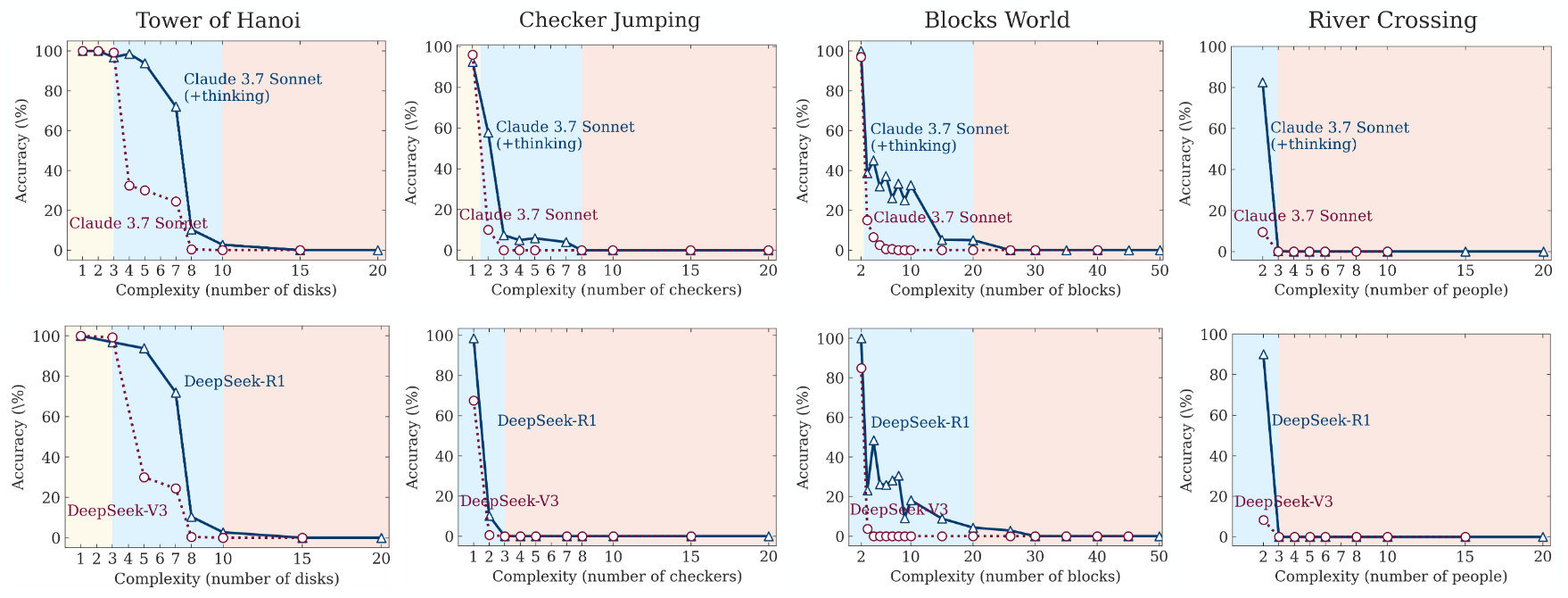
Lo que es más sorprendente aún es que en el caso de las torres de Hanoi estos resultados no mejoran incluso si al LLM se le proporciona en el prompt el pseudocódigo del algoritmo que puede ejecutar para encontrar la solución al problema. En vista de esto, los autores concluyen que incluso los LLM razonadores no son capaces de realizar un auténtico razonamiento, y que la pérdida de capacidades al aumentar la dificultad de los puzles puede deberse a la falta de soluciones en internet de ese nivel de complejidad.
¿Contamos entonces ya con un test definitivo para los LLM? Mi opinión es que no, dado que los LLM del estado del arte ya son más bien “agentes” por defecto, y suelen incorporar por defecto herramientas como intérpretes de python. Basta entonces con que empiecen a localizar por internet descripciones de las torres de Hanoi junto el código python de la solución para que puedan resolver el problema, independientemente del grado de dificultad. Y más fácil aún con la tarea de la multiplicación vista arriba; de hecho, si hoy día usamos ChatGPT con el “modo agente” activado, podemos ver cómo abre un intérprete de python y realiza el cálculo ahí, obteniendo así la solución correcta.
Y es por todos estos motivos, y también por pique personal, por el que decidí embarcarme en la aventura de crear…
BaLLMatro

BaLLMatro es un tarea para evaluar LLM (y sistemas de IAs en general), inspirado en el videojuego Balatro. En BaLLMatro se simula una versión muy simplificada del póker, donde recibimos una serie de cartas y debemos elegir cuáles de ellas jugar, con el fin de maximizar la puntuación obtenida. Esta puntuación se determina en varios pasos, teniendo en cuenta tanto el tipo de mano de póker que hayamos jugado, como las cartas concretas que la conforman.
En primer lugar, se analiza qué mano hemos jugado (póker, escalera, dobles parejas, etc…) , y ésta nos aporta una serie de fichas (chips) y un multiplicador. Mientras mejor sea la mano, mayores serán estos valores: por ejemplo un póker nos da 60 chips y 7 de multiplicador, mientras que un trío nos daría 30 chips y 3 de multiplicador.
Tras esto, los valores de fichas y multiplicador conseguidos pueden modificarse en función de las cartas concretas jugadas (A♣, J♥, 7♦, 4♠, …). El as es la carta más valiosa (11 chips), mientras que el resto de figuras (K, Q, J) dan 10 chips, y las cartas numéricas aportan una cantidad de chips igual a su número. Además, existen algunas cartas especiales que pueden incluir modificadores (ej: 2♣+) y dan aportes extra en chips o multiplicador. Tras añadir todos estos aportes, la puntuación final se determina calculando el producto de las fichas por el multiplicador.
Las reglas completas de puntuación están disponibles en inglés en el repositorio del proyecto. Un ejemplo de puntuación sería el siguiente: supongamos que recibimos las siguientes cartas
[2♣, 5♥, 5♣, J♣, J♦]podemos entonces realizar la siguiente jugada
[5♥, 5♣, J♣, J♦]la cual es una mano de dobles parejas, cuyo valor es de 20 chips y un multiplicador de x2. Las cartas jugadas ahora nos otorgan 5 chips (5♥) + 5 chips (5♣) + 10 chips (J♣) + 10 chips (J♦) = 30 chips, que se suman a los que ya habíamos conseguido por jugar dobles parejas (20 + 30 = 50 chips). Por tanto, la puntuación final de esta jugada serían 50 chips · 2 multiplicador = 100 puntos.
Análisis de complejidad de BaLLMatro
Aunque las reglas puedan parecer algo complejas a primera vista, en realidad el encontrar la mejor jugada posible se reduce a un problema de optimización: probar todos los subconjuntos posibles de cartas, calcular para cada uno la puntuación que se obtendría, y efectuar la jugada con la mayor puntuación prevista. Como veremos, si las cartas que nos ofrecen son pocas, es fácil para una persona leerse las reglas del juego y determinar cuál es la mejor jugada. Pero a medida que aumenta el número de cartas, aumenta también el número de posibles jugadas, complicando el problema. En este sentido, BaLLMatro se comporta de manera similar a los puzles empleados en el paper de Apple mencionado antes, donde podemos aumentar exponencialmente la complejidad del problema incrementando el número de elementos.
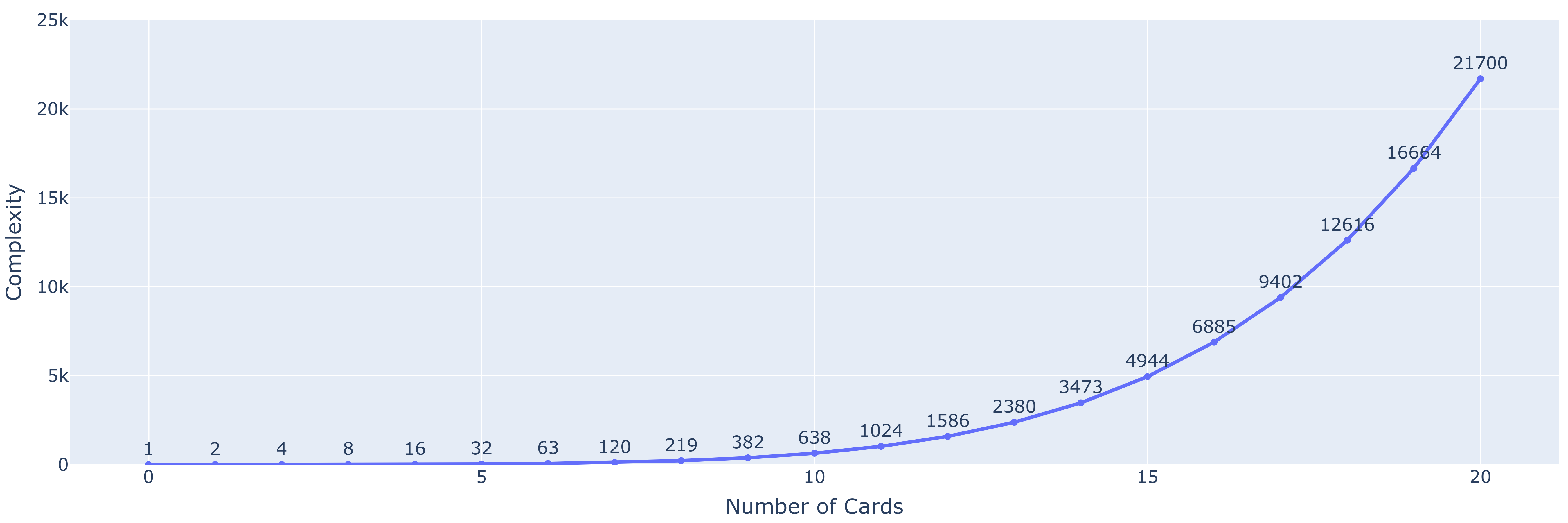
Al igual que ocurrió en el caso de las torres de Hanoi y otros puzles testeados por los investigadores de Apple, un LLM debería tener cada vez más problemas para encontrar la solución correcta a medida que aumenta el número de cartas disponibles. No obstante, hay que destacar que dado que el número de cartas de póker es finito, y que no hay manos de póker con más de 5 cartas, por mucho que queramos complicar este problema existe un máximo al número de posibles jugadas que tiene sentido intentar realizar. Concretamente:
Las cartas existentes son: 13 figuras · 4 palos · 3 variantes según multiplicador = 156 cartas.
El número de manos posibles de k cartas corresponde al número de combinaciones con repetición de k elementos tomados (con repetición) de un conjunto de 156, lo cual se calcula como C(156+k-1,k), con C el coeficiente binomial.
Dado que existen manos de 1, 2, 3, 4 y 5 cartas, una cota superior al número de jugadas que tendría sentido intentar serían C(156,1) + C(157,2) + C(158,3) + C(159,4) + C(160,5) = 846.678.391 jugadas.1
Por tanto, aunque existe un límite superior a la complejidad de este problema, es lo suficientemente alto como para no suponer una traba en los experimentos que se van a realizar aquí.
Por otro lado, un factor innovador de BaLLMatro es que además de la capacidad de modular la complejidad de la tarea aumentando el tamaño del espacio de búsqueda, este desafío permite también aumentar la dificultad de comprensión del problema, retando al LLM (y a los humanos) a tener que interpretar reglas más complicadas. Pero no nos adelantemos, veamos de momento cómo se comportan diversos LLM al tratar de afrontar el desafío con las reglas explicadas hasta ahora.
BaLLMatro nivel 1
Dentro del proyecto BaLLMatro existen una serie de desafíos ya preparados y organizados según su nivel de dificultad. Estos desafíos están disponibles como datasets de Hugging Face, lo que facilita su reutilización y que cualquiera pueda abordarlos fácilmente. El desafío del primer nivel es muy sencillo: tan solo se recibe una única carta. Por ejemplo:
[5♥]Ante esta situación, lo único que debería hacer la IA siendo evaluada es jugar exactamente la carta que ha recibido. Un algoritmo que dé solución a este nivel de dificultad es trivial, y consistiría en simplemente copiar el string de entrada en la salida. No obstante, estaremos poniendo a prueba la capacidad de compresión del sistema de IA, que a raíz de interpretar las reglas del juego debe llegar a la conclusión de que, efectivamente, esta es la estrategia óptima.
Los LLM que vamos a evaluar son una muestra tanto de modelos open-source como comerciales:
Qwen2.5: creados por Alibaba en septiembre de 2024, han demostrado muy buen rendimiento en múltiples idiomas. Evaluaremos aquí los tamaños 0.5B, 7B y 32B.
Qwen3-Instruct: mejorando sobre los Qwen2, en julio de 2025 Alibaba presentó los modelos Qwen3, los cuales están diseñados para poder generar cadenas de razonamiento. Sin embargo, para esta primera prueba emplearemos los modelos “Instruct” de esta familia, los cuales han sido especializados en no generar tal cadena y ser así más eficientes en inferencia. Evaluaremos los tamaños 4B y 30B-A3B (30 mil millones de parámetros en el modelo, con activación de solo 3 mil millones por token procesado).
gpt-4o: modelo propietario de OpenAI, publicado en mayo de 2024, y que hasta la aparición de gpt-5 era el modelo por defecto de ChatGPT. Y de hecho, tan acostumbrado estaba el público general a usar este modelo, que OpenAI tuvo que restaurarlo como opción en ChatGPT, tras intentar reemplazarlo completamente por gpt-5. Evaluaremos las versiones mini y completa.
gpt-4.1: casi 1 año más actual que gpt-4o (abril de 2025), la versión 4.1 ha demostrado mejores resultados a un coste reducido. Además está disponible en 3 tamaños, nano, mini y completo, todos sujetos a evaluación.
Hechas las presentaciones, veamos qué tal se desempeñan estos modelos sobre los 78 casos de test disponibles para el nivel 1 de BaLLMatro:
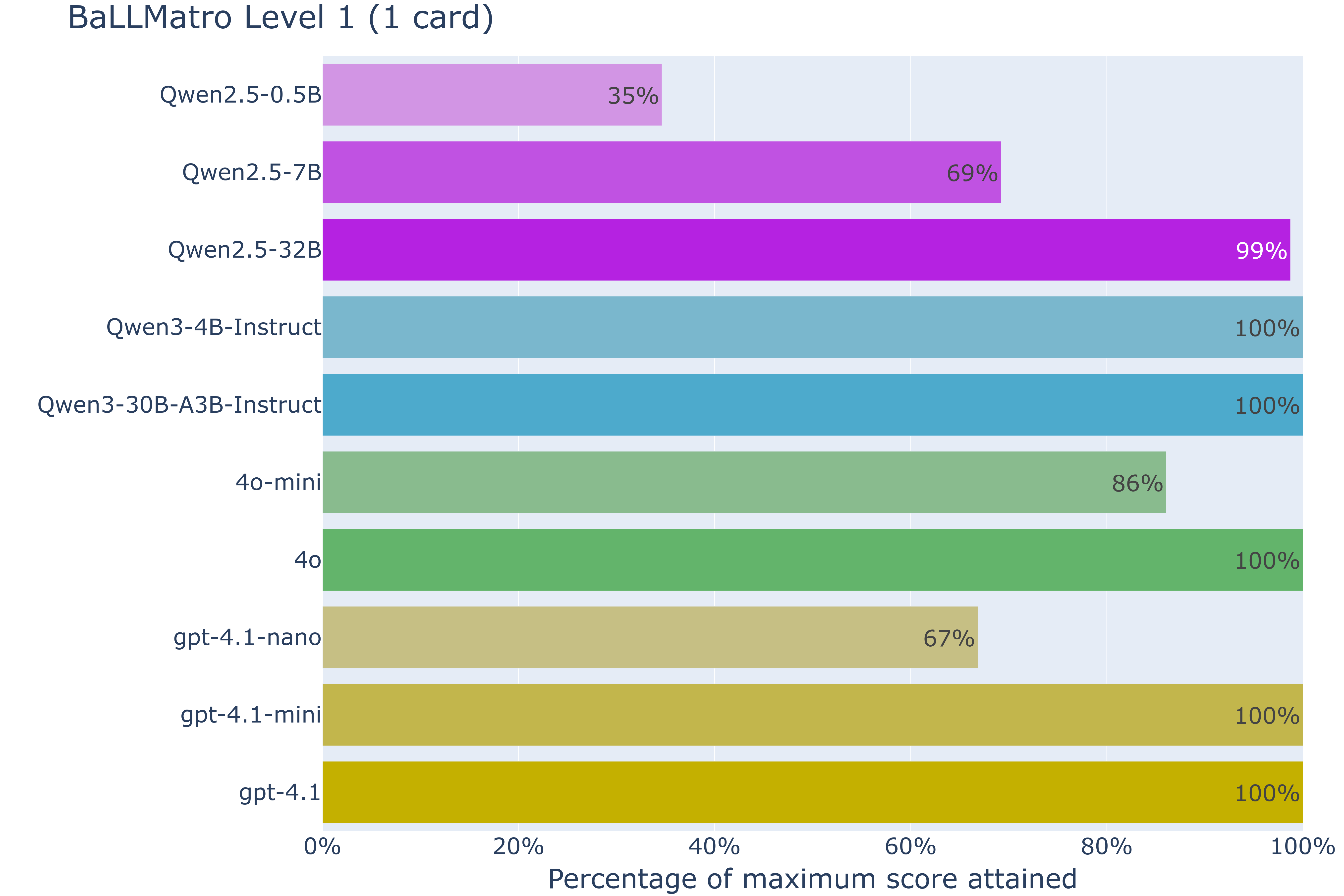
Podemos comprobar cómo los modelos más pequeños (Qwen2.5-0.5B, Qwen2.5-7B, 4o-mini, 4.1-nano) producen resultados pobres, quedando lejos de poder resolver a la perfección un desafío tan sencillo. El motivo de esta falta de rendimiento se debe tanto a generaciones del resultado en formato incorrecto, como a la generación de jugadas similares a las presentes en los ejemplos de las instrucciones pero que no guardan relación con las cartas recibidas.
Por otra parte, es muy notorio que en el último año la capacidad de los modelos ha mejorado notablemente: 4.1-mini puede resolver perfectamente lo que 4o-mini no podía, y los modelos Qwen3 también obtienen resultados perfectos cuando los de su generación anterior no lo lograban.
Una vez comprobado que incluso en su mínima expresión esta tarea ya resulta problemática para algunos de los modelos más populares, vamos a subir el nivel de dificultad.
BaLLMatro nivel 2
En el nivel 2 nos presentan dos cartas con las que jugar, y por tanto debemos decidir si jugar ambas, solo la primera de ellas, o solo la segunda. Algunos ejemplos de entrada y salida óptima serían:
[2♣, 5♣] -> [5♣]
[J♦, 5♥] -> [J♦]
[5♥, 5♣] -> [5♥, 5♣]
[3♣x, A♣] -> [3♣x]El algoritmo de decisión óptimo en este caso es jugar ambas cartas si con ellas podemos formar una pareja (coincidencia en rango), y en caso contrario jugar únicamente la carta de mayor valor. Nótese que este “mayor valor” no depende solo del rango de la carta, sino que también deben tenerse en cuenta posibles modificadores (“+” y “x”). Por tanto, es necesario implementar una cierta lógica que tenga en cuenta las reglas de puntuación para dar con la jugada óptima.
Poniendo a prueba a los mismos LLM que en el nivel anterior nos encontramos lo siguiente:
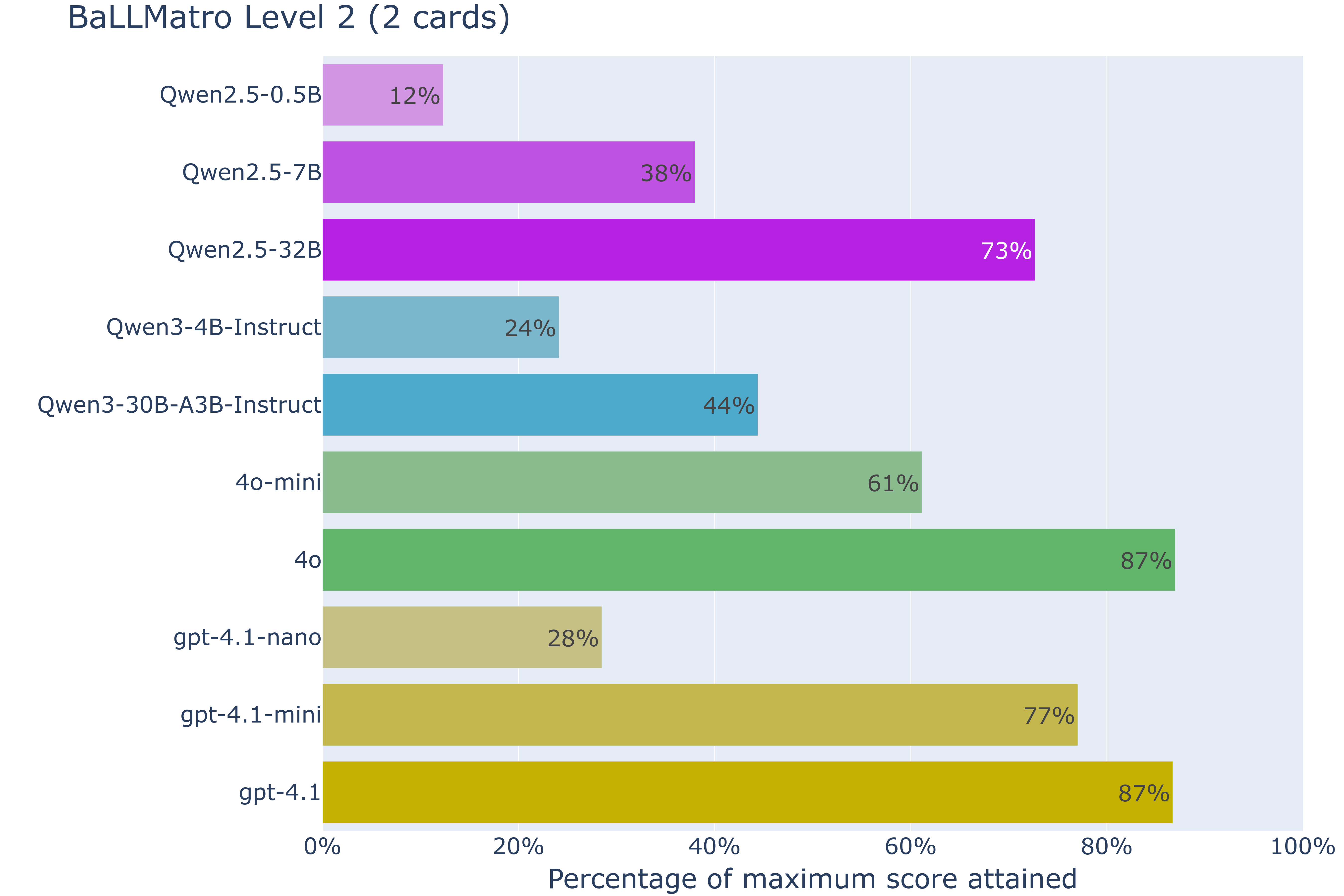
Sorprendentemente, observamos una caída de rendimiento generalizada en todos los modelos, incluso en aquellos donde teníamos un rendimiento perfecto en el nivel anterior. Si examinamos el detalle de los resultados podemos ver que por ejemplo gpt-4.1 tiende muchas veces (9.6% de casos) a jugar ambas cartas, aunque no formen una pareja. Parece por tanto que incluso el modelo más potente bajo evaluación no es capaz de interpretar correctamente las normas del juego.
BaLLMatro niveles 3 y 4
En el nivel 3 pasamos a recibir 4 cartas en cada partida, lo que habilita jugar todas las manos de póker salvo la escalera, full house, color y escalera de color, y nos permite realizar 16 jugadas posibles. Progresando sobre esto, en el nivel 4 el tamaño de la mano aumenta a 8 cartas, permitiendo ahora todas las manos de póker y aumentando la complejidad del problema a 219 jugadas posibles. Visualizando de forma conjunta los resultados de los 4 niveles vistos hasta ahora, tenemos el siguiente escenario:
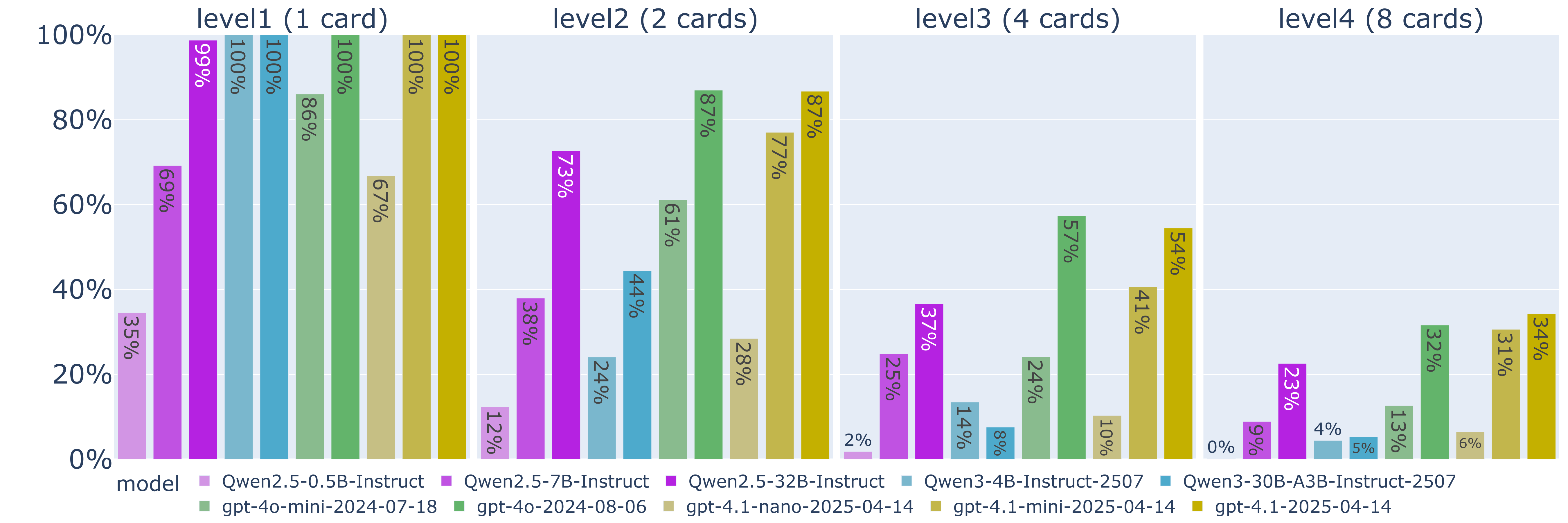
Cada nivel de complejidad ha perjudicado significativamente el rendimiento de todos los LLM, llegando incluso al 0.1% de puntuación en el caso del modelo más pequeño (Qwen2.5-0.5B), que es incapaz de realizar una jugada válida en el 99.6% de los casos. Por otro lado, el mejor modelo (gpt-4.1) se limita a un 34% de puntuación, con un 53.2% de jugadas inválidas.
Parece por tanto que los LLM se nos han quedado cortos muy rápido. Aunque por supuesto, se podría argumentar que aquí no hemos usado “lo último de lo último”, ya que en este benchmark no hemos incluido ningún LLM razonador, y cabría preguntarse si estas capacidades de razonamiento pueden ayudar a resolver este problema. Vamos a ello.
LLM razonadores
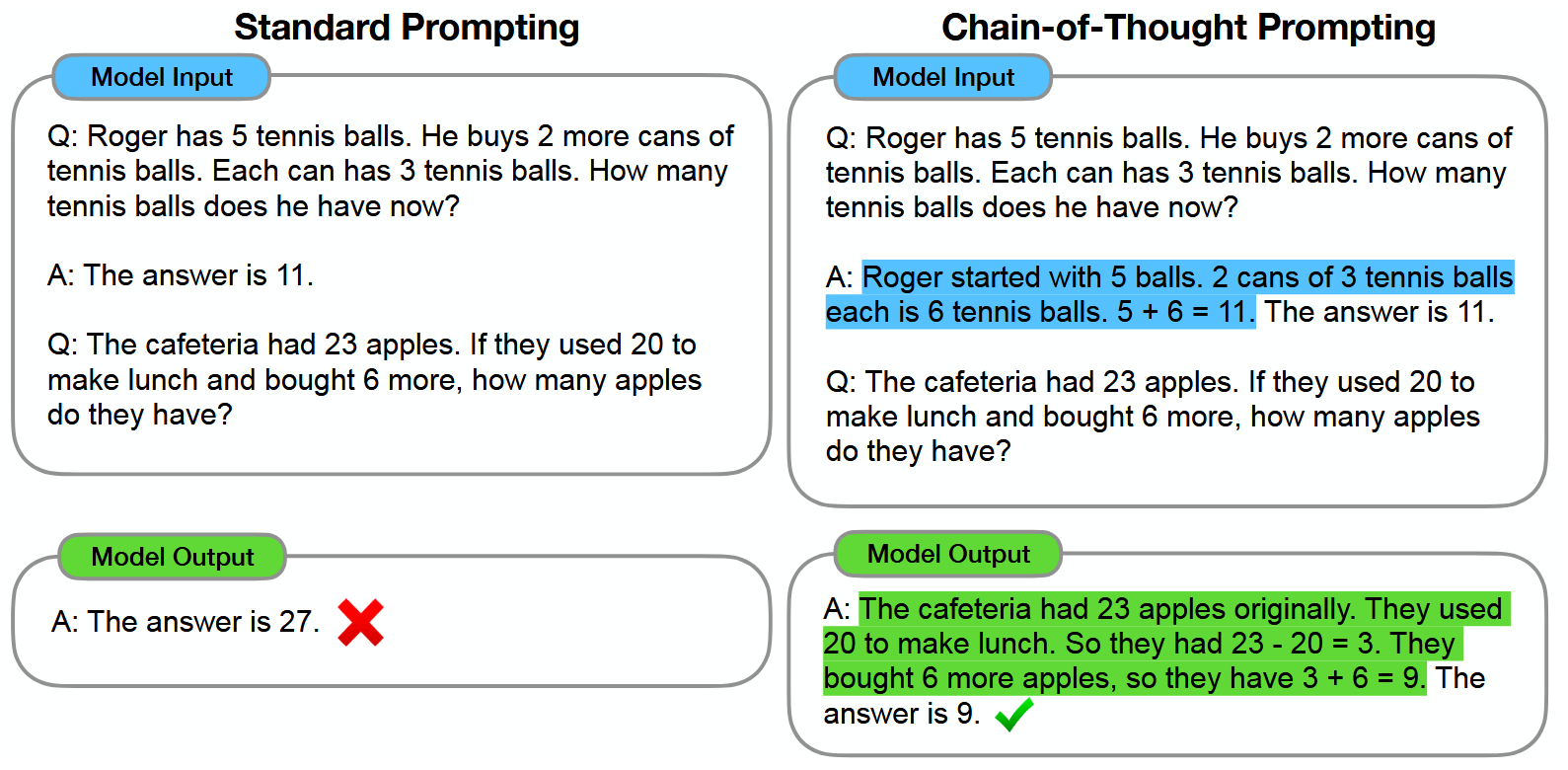
Como brevísima introducción para los que no conozcan este tipo de LLM: esencialmente se basan en emplear un formato de prompt y entrenamiento conocido como Chain of Thought, o cadena de pensamiento/razonamiento. Esta idea se introdujo en un paper sencillo pero brillante (Wei et al.), y puede resumirse en la figura que encabeza esta sección: formatear los datos de entrenamiento para que no incluyan únicamente la pregunta del usuario y la respuesta que debería dar el LLM, sino incluir también una sección intermedia de “pensamiento” en la que se explique paso a paso cómo llegar a la solución. En LLM recientes esta sección de pensamiento suele ir enmarcada en etiquetas del tipo <think> </think> o similar, de forma que sea fácil identificar qué parte del texto generado por el LLM corresponde a su “razonamiento” y cuál a la respuesta final.
Entrenar un LLM con datasets que incluyan cadenas de razonamiento no hace que el LLM obtenga la capacidad emergente de razonar, pero sí que sea capaz de aprender una multitud de pasos que puede reutilizar para resolver un problema complejo. Podríamos decir entonces que el LLM es capaz de interpolar razonamientos vistos previamente para darnos una respuesta. Y como siempre ocurre en los LLM, que esto resulte en una cadena de razonamiento correcta o que se dedique a hilar sandeces dependerá de lo cerca que esté nuestra pregunta de lo visto durante ese entrenamiento. No obstante, siempre puede mejorarse la probabilidad de que el LLM genere la respuesta correcta en ciertos ámbitos si contamos con evaluaciones verificables y las explotamos mediante aprendizaje por refuerzo con algoritmos como GRPO.
Vistos entonces los fundamentos, presentamos los LLM razonadores que vamos a emplear en la comparativa, contando de nuevo con una mezcla de modelos open-source y comerciales:
Qwen3: la gran mayoría de modelos Qwen3 han sido entrenados para generar una cadena de razonamiento, pero son especialmente destacables los modelos “Thinking”, los cuales han recibido un entrenamiento adicional para mejorar sus capacidades. Aquí emplearemos los modelos Qwen3-0.6B, Qwen3-8B y Qwen3-4B-Thinking.
gpt-oss: OpenAI sorprendió a todos cuando en agosto de 2025 publicó dos modelos con licencia Apache 2.0, equipados con capacidades para razonar y empleando un tipo de datos MXFP4, muy eficiente para tarjetas GPU de la gama Hopper (H100/H200 y RTX5000). Evaluaremos aquí los dos modelos publicados, gpt-oss-20b y gpt-oss-120b.
o4-mini: se trata de un modelo razonador de alto rendimiento pero bajo coste, publicado por OpenAI en abril de 2025. Fue el último miembro de la familia “o”, los modelos razonadores de OpenAI, antes de que llegara gpt-5, y se presentaba como una alternativa más eficiente y rentable al poderoso pero caro modelo o3.
gpt-5: no podría faltar a la fiesta la última iteración de GPT, presentada en agosto de 2025 y con la que abríamos este artículo. gpt-5 es un modelo razonador por defecto, aunque mediante opciones de configuración puede modularse cuánto tiempo queremos que se pase pensando la respuesta. En esta evaluación emplearemos únicamente las versiones gpt-5-nano y gpt-5-mini, por motivos que quedarán patentes más adelante. En ambos casos emplearemos la configuración de razonamiento por defecto.
Lanzando todos estos modelos contra los niveles 1 a 4 de BaLLMatro, y comparando contra los mejores LLM no razonadores, obtenemos estos resultados:
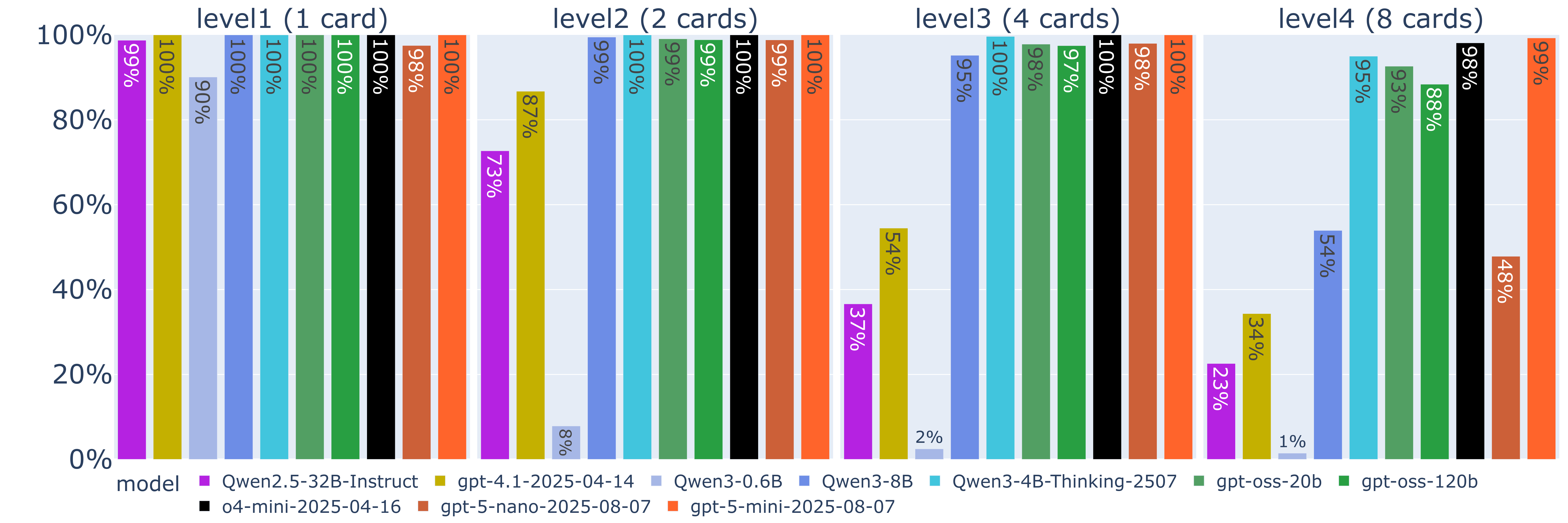
En los niveles 1 a 3 casi todos los LLM razonadores obtienen un puntuación prácticamente perfecta, con la excepción de Qwen3-0.6B, que rápidamente colapsa y lo hace peor incluso que los LLM estándar. Es además reseñable que Qwen3-4B-Thinking funciona excepcionalmente bien, superando a otro modelo Qwen3 de mayor tamaño e incluso a los modelos open-source de gpt, y quedándose cerca de los modelos cerrados de gpt más potentes, o4-mini y gpt-5-mini. Estos últimos son los claros ganadores, demostrando una puntuación casi perfecta incluso en el nivel 4.
Parece por tanto que los LLM de razonamiento más capaces sí son capaces de superar el desafío con éxito. Pero lo único que significa eso, ¡es que tenemos que aumentar el nivel de dificultad! Y para ello vamos a hacer uso, ahora sí, de la otra mecánica que posee BaLLMatro para hacer el desafío más complejo.
Jokers

Una innovación clave del videojuego Balatro, en el que se inspira BaLLMatro, son los jokers. Estas son cartas especiales que podemos adquirir durante la partida, las cuales modifican las reglas de puntuación. Por ejemplo, un joker puede hacer que las cartas del palo ♥ otorguen un multiplicador extra, o que aumente el número de chips obtenidos si la mano jugada es de un tipo concreto. Existen 150 jokers diferentes en Balatro, así como otros tipos de cartas que también afectan a la puntuación, como las cartas de planeta, fomentando así que las reglas de cada partida sean diferentes.
BaLLMatro incorpora esta mecánica permitiendo que en las cartas de entrada de cada jugada puedan aparecer también cartas de joker, como en el siguiente ejemplo:
[🂿 Pluto: multiplies by 2 the chips and multiplier of the High Card hand, 2♥,2♦,A♠]Las cartas de joker se identifican por el carácter especial 🂿, y van siempre seguidas del nombre del joker y una descripción de su efecto. Estas cartas no pueden incluirse en la mano de póker a jugar, pero alteran las reglas de puntuación, de forma que la jugada óptima puede no ser la misma que si no hubiéramos recibido ese joker. Sin ir más lejos, en el ejemplo presentado la jugada óptima es [A♠], ya que aunque de normal esto nos proporcionaría 5+11 chips · 1 multiplicador = 16 puntos, al incluir el efecto del joker tenemos 5·2+11 chips · 1 · 2 multiplicador = 42 puntos.
El desafío por tanto radica en que en cada caso a resolver podemos encontrarnos jokers que alteren en el momento las reglas de juego, y el LLM debe tener la suficiente capacidad de compresión del lenguaje para encontrar la jugada óptima bajo las nuevas reglas.
Aunque este mecanismo aporta una nueva dimensión al problema, también dificulta el desarrollo. Mientras que para aumentar el espacio del búsqueda basta con cambiar un parámetro (el número de cartas), para aumentar el número de jokers es necesario implementar en código la forma en la que modifican las reglas, de forma que se pueda evaluar de manera determinista y fiable la puntuación de cada jugada del LLM. A pesar de esto, nos liamos la manta la cabeza y nos ponemos a programar, creando así nuevos niveles de dificultad.
BaLLMatro nivel 5
En el nivel 5 sacamos partido a esta nueva dimensión de complejidad, contando de nuevo con una mano de 8 cartas en cada prueba, pero pudiendo esta incluir también un joker de entre una librería de 10 jokers diferentes. Puede parecer un cambio de poca entidad, pero no lo es: dado que los efectos concretos de estos jokers no están especificados en las reglas del juego, sino que se descubren solo en el momento en el que aparecen en la mano, el LLM debe ser capaz de inferir en ese instante cómo cambiar su estrategia.
Es también importante destacar que mientras que en niveles anteriores era posible obtener una puntuación perfecta desarrollando un programa que probara a fuerza bruta todas las jugadas posibles y emitiera la de mayor puntuación, en este caso esta estrategia no sería válida, dado que no pueden conocerse los jokers hasta que no se pone a prueba el sistema desarrollado.
Descartando ya los LLM no razonadores en vista de su pobre rendimiento, evaluamos en este nivel solo los modelos con cadena de razonamiento:
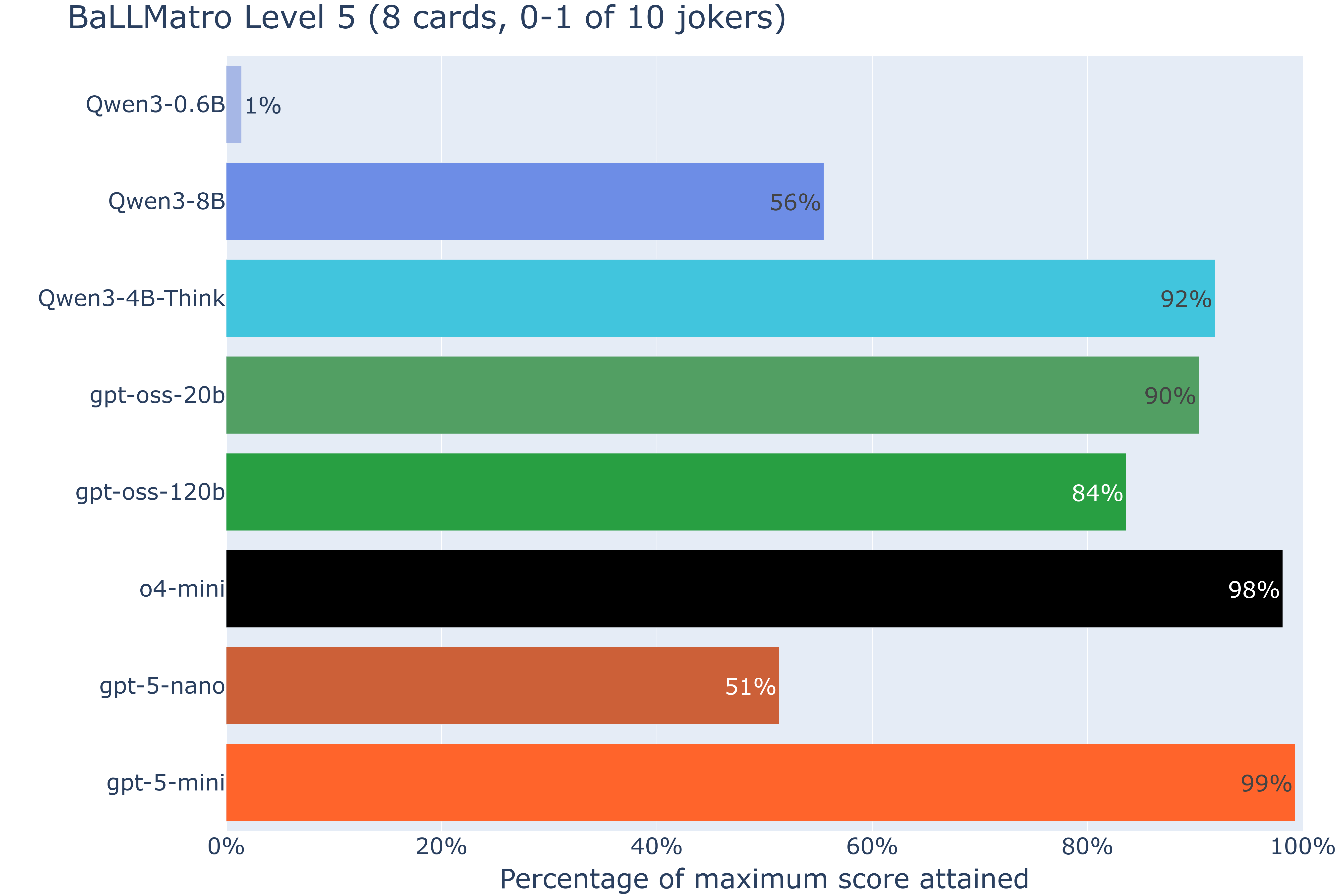
Las puntuaciones obtenidas son solo ligeramente peores que las del nivel 4, por lo que parece que los modelos razonadores no se han visto impactados al encontrarse con estos jokers en las cartas de entrada. No obstante, en este nivel el efecto de los jokers es aún muy pequeño: una solución que los ignorase por completo y optimizara únicamente en base a las reglas básicas del juego podría obtener una puntuación del 99.8%. Necesitamos entonces presionar aún más.
BaLLMatro niveles 6 y 7
Pisando más el acelerador vamos a por dos niveles aún más complejos:
Nivel 6: se aumenta la variabilidad y cantidad de jokers, pasando cada mano a tener entre 0 y 2 jokers, extraídos de un conjunto de 37 jokers diferentes.
Nivel 7: aumentamos el número de cartas por mano a 9, subiendo así el tamaño del espacio de búsqueda a 382 posibles jugadas, y cada mano incluye entre 1 y 3 jokers, muestreados de un conjunto de 110 jokers diferentes.
Veamos los resultados comparativos de los niveles con jokers (5 a 7), marcando también cuál sería la puntuación máxima en cada nivel si se ignorasen los jokers:
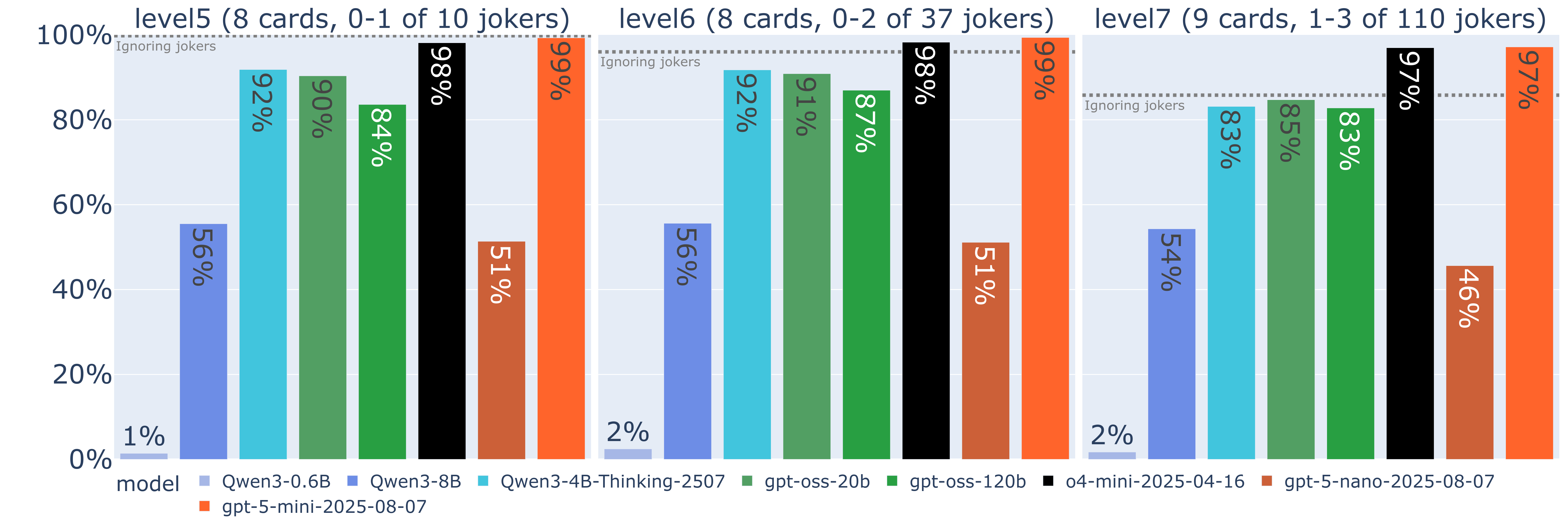
El hecho de añadir más jokers en el nivel 6 apenas impacta en el rendimiento de los modelos, incluso si ahora sí que existe una penalización notoria si estos se ignoran en las jugadas. Se confirma de esta forma que los LLM de mayor rendimiento (o4-mini y gpt-5-mini) sí que están siendo capaces de adaptarse a cambios de reglas producidos por los jokers.
Llegando al nivel 7, donde aumenta significativamente tanto el tamaño del espacio de búsqueda como la cantidad y variedad de jokers, apreciamos solo una ligera caída de puntuación en todos los modelos. En esta ocasión ignorar los jokers limita la puntuación máxima a un 85.8%, y aunque los mejores modelos parecen estar lidiando con esta situación sin problemas, no es así para modelos como los Qwen y gpt-oss, que se ven empujados por debajo de esta barrera.
BaLLMatro nivel X
Vista la tremenda capacidad de adaptación y optimización demostrada por los mejores modelos razonadores, como último desafío subimos desproporcionadamente el nivel de dificultad, y planteamos un nivel con 14 cartas por mano (3473 posibles jugadas), y entre 5 y 10 jokers, muestreados de un conjunto de 110 jokers diferentes. El objetivo aquí sería encontrar el punto en el que los LLM de mayor capacidad rompen, midiendo así dónde está su límite.
Para este caso y por razones de tiempo y coste vamos a experimentar únicamente con los 3 LLM que mejores resultados han dado dentro de cada familia: Qwen3-4B-Thinking, gpt-oss-20b y gpt-5-mini De esta manera obtendríamos los siguientes resultados:
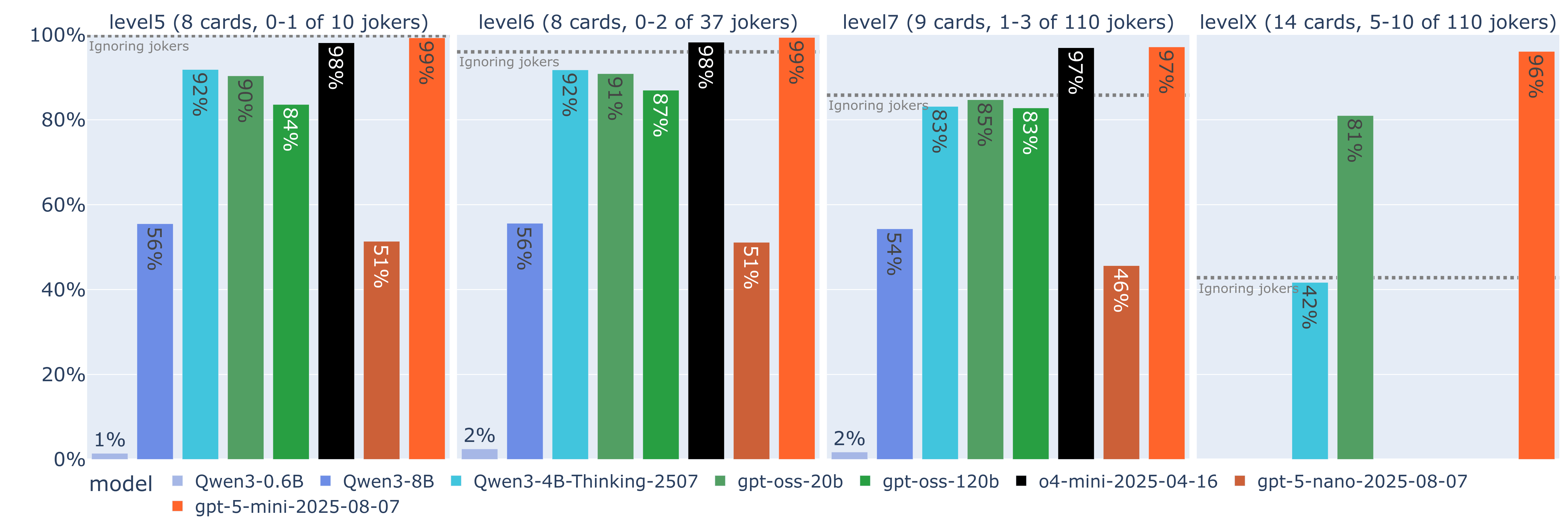
En este caso el ignorar las instrucciones de los jokers supondría una penalización de más del 57.2% de la puntuación, y observando el rendimiento de Qwen3-4B-Thinking podemos constatar que este parece haber sido el caso. Pero por otro lado, el impacto en la puntuación de gpt-oss-20b y gpt-5-mini respecto del nivel anterior es mínima. Parece por tanto que, sorprendentemente, estos LLM han sido capaces de superar el desafío. La cuestión es, ¿cómo han podido hacerlo?
No podemos abrir la caja de gpt-5 y analizar sus entrañas, dado que funciona a través de una API cerrada. Pero sí podemos hacerlo con gpt-oss-20b, analizando los tokens de pensamiento que ha generado para tomar sus decisiones. Por ejemplo, tomemos el siguiente caso de test del nivel X:
[🂿Empowered Seven: Double the chips and multiplier for cards with rank 7, 🂿Fibonacci: Double the chips and multiplier for cards with Fibonacci rank (1 2 3 5 8), 🂿Mercury Shard: Adds 1 to the chips and multiplier of the Pair hand, 🂿Oddity: Double the chips and multiplier for cards with odd rank (1 3 5 7 9), 🂿Mars Shard: Adds 1 to the chips and multiplier of the Four of a Kind hand, 9♦, 7♦, A♣x, 7♥x, 5♠, Q♥, 6♦+, 8♥+, J♦, 5♠x, K♦x, 5♥x, 9♥+, A♣]La jugada óptima en este caso es la escalera [5♠x, 6♦+, 7♥x, 8♥+, 9♥+], pero esto no es obvio dada la cantidad de cartas disponibles y de jokers que modifican las reglas de puntuación. A la hora de enfrentarse a este problema, gpt-oss-20b genera una cadena de pensamiento bastante extensa, de unos 27.000 caracteres, lo que hace que tarde un tiempo considerable en tomar su decisión. La cadena completa está disponible aquí; en este artículo resumiremos los pasos principales que sigue, y que son los siguientes:
Listar las cartas recibidas que no son jokers.
Listar las cartas recibidas que son jokers.
Para cada jugada de póker posible (escalera, full house, …), analizar si puede hacerse con las cartas recibidas.
Analizar el efecto que cada multiplicador y cada joker tiene en la puntuación.
Revisar las reglas de puntuación.
Calcular la puntuación que aporta cada carta, teniendo en cuenta modificadores y jokers.
Para una serie de jugadas posibles, realizar paso a paso los cálculos para obtener la puntuación que otorgará cada una de ellas. Concretamente se analizan las siguientes jugadas:
Full House con 5♠,5♠x,5♥x,9♦,9♥+.
Escalera de 5 a 9.
Escalera de 7 a Q.
Triple 5.
Distintas combinaciones de parejas.
Reconsiderar las jugadas del punto anterior y buscar posibles alternativas.
Revisar el cálculo de la puntuación de la mejor jugada encontrada, para confirmar que es correcto.
Asegurar el formato en el que se va a escribir el resultado.
Generar el resultado.
Aunque el detalle del razonamiento generado es muy caótico, con el LLM replanteándose constantemente las reglas del juego y los cálculos ya realizados, resulta muy sorprendente que a alto nivel la estrategia que toma es bastante apropiada. Únicamente en base a las reglas del juego ha sido capaz de establecer una heurística para buscar una buena solución, sin tener que caer en una búsqueda exhaustiva.
Con el fin de aportar más evidencias, puede consultarse aquí otra cadena de razonamiento, donde se comprueba que los pasos seguidos son similares para el segundo caso de test:
[🂿Uranus+: Multiplies by 5 the chips and multiplier of the Two Pair hand, 🂿Neptune+: Multiplies by 5 the chips and multiplier of the Straight Flush hand, 🂿Banned Ten: Played cards with rank 10 will be ignored in poker hand determination and scoring, 🂿Jupiter+: Multiplies by 5 the chips and multiplier of the Flush hand, 🂿Populism: Double the chips and multiplier for cards with non-figure rank (1 to 10), 5♥+, 6♣, 10♣x, 3♦+, 9♣, 5♥, 7♦+, A♣x, 7♦, 5♦+, Q♦x, 8♥, 10♥x, 3♣x]Bonus track: especialización

Una idea que defiendo habitualmente es que pretender emplear un LLM de gran tamaño para absolutamente todo es un uso ineficiente de esta tecnología. Ciertamente, un modelo como gpt-5 demuestra gran capacidad de resolver todo tipo de tareas, y es extremadamente efectivo para realizar pruebas de concepto de manera rápida. Pero el consumo de recursos computacionales (y dinero) que acarrea puede ser un problema para la escalabilidad en muchos casos prácticos. Sin ir más lejos, gpt-5-mini tardó aproximadamente 2 días completos en realizar todos los razonamientos necesarios para resolver las 1000 preguntas del nivel X de BaLLMatro, ¡y ni siquiera estamos hablando del modelo gpt más grande! En cambio, un modelo no razonador de pequeño tamaño como Qwen2.5-0.5B tan solo requiere de 5 minutos en una GPU A100… aunque como hemos podido comprobar, sus resultados en este problema dejan mucho que desear.
Una técnica clave que podemos explotar para aproximar el rendimiento de un pequeño modelo de lenguaje al de un gran modelo razonador es la especialización, o más técnicamente, el ajuste fino supervisado (Supervised Fine Tuning, SFT). En el fondo esto no es ningún misterio, sino que es la técnica que siempre se ha empleado en aprendizaje automático para que un modelo de IA aprenda a realizar una tarea concreta; la diferencia es aquí no partimos de un modelo “vacío”, sino que podemos basarnos en un LLM de tamaño pequeño.
Aprovechando que BaLLMatro cuenta con datasets separados de entrenamiento (train) y test para todos los niveles, podemos realizar un aprendizaje supervisado de LLM pequeños no razonadores sobre la partición de train, para luego medir cómo han mejorado sus resultados sobre el test. Concretamente, para estos experimentos he realizado un entrenamiento de 3 épocas sobre estos datos, haciendo uso de un adaptador LoRA de rango 64 para solo modificar parcialmente el LLM original (y por motivos de costes de entrenamiento). La siguiente gráfica muestra las mejoras que aporta el proceso de SFT sobre los LLM de pequeño tamaño Qwen2.5-0.5B-Instruct, Qwen2.5-7B-Instruct y Qwen3-4B-Instruct, incluyendo también como referencia el rendimiento de los modelos razonadores Qwen3-4B-Thinking y gpt5-mini:
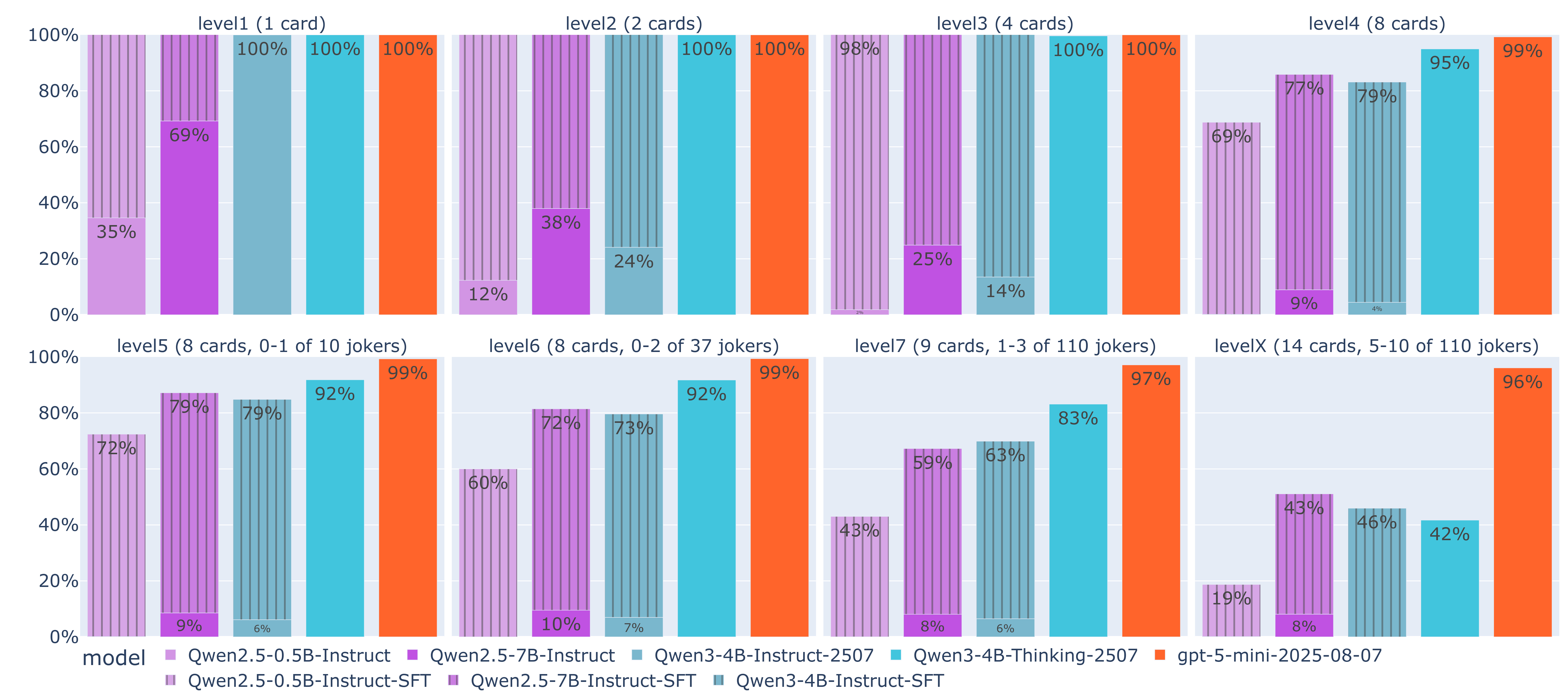
El efecto de especialización del SFT es muy significativo: del nivel 1 al 3 es posible alcanzar aciertos similares a los de los modelos razonadores, y en niveles superiores aunque los modelos razonadores tienden a llevar la delantera, la mejora obtenida por esta especialización es muy significativa. ¡En el nivel de dificultad más alto incluso se supera a un modelo razonador! Y todo ello manteniendo una alta velocidad de inferencia.
Conclusiones

Vivir hoy en el mundo de la IA implicar habitar una constante disonancia cognitiva, con nuevos records en benchmarks altamente complejos sucediéndose cada semana, mientras al mismo tiempo observamos fallos catastróficos de los LLM en nuestra actividad profesional y cotidiana. Esta aparente doble realidad se concilia únicamente al darnos cuenta de que los LLM son una inteligencia “dentada” o “serrada”, con picos de brillante habilidad rodeados de fosas de profunda estupidez.
Al crear BaLLMatro como un desafío que antes no existía mi intención era medir de manera más justa las capacidades de estos LLM. Los resultados han sido muy sorprendentes: mientras que LLM de hace apenas 1 año fallan estrepitosamente incluso en los niveles más sencillos, los modelos razonadores más recientes han demostrado una capacidad que no esperaba encontrarme, en especial gpt-5.
Tal vez BaLLMatro haya sido un desafío demasiado fácil para los modelos que se han entrenado mediante cadenas de razonamiento, de forma que estén pudiendo reutilizar estrategias y heurísticas que han aprendido de otros juegos o problemas de decisión. Pero en base a mi experiencia profesional sigo convencido de que incluso LLM así de avanzados cometen errores tremendos e incomprensibles cuando se les saca demasiado de su región de datos de entrenamiento, algo especialmente notorio cuando se trabaja con datos privados y problemas particulares de cada sector profesional. Tendremos por tanto que seguir trabajando en nuevas formas de evaluación que nos permitan distinguir más claramente dónde se encuentran los picos y los valles de este paisaje tan complicado y cambiante.
Créditos
Agradecimientos al Instituto de Ingeniería del Conocimiento por proporcionar el hardware y los créditos de OpenAI para poder realizar estos experimentos.
Imágenes de apoyo creadas con Sora.
Curiosamente, gpt-5 es capaz de realizar todo este cálculo matemático correctamente. Otro punto a favor de las capacidades que ha demostrado a lo largo de este experimento.
Gran post! olé por gpt-5 llega hasta la prueba final imbatido.
Va a ver paper? Ya me entra la duda si con este post, y el repositorio de GitHub es preciso otro papel más?
Gracias por la perspectiva incisiva sobre el tema, Álvaro.
Una cosa: el concepto de "inteligencia dentada " (jagged intelligence) es de Ethan Mollick hasta donde yo sé:
https://www.oneusefulthing.org/p/centaurs-and-cyborgs-on-the-jagged